지난 글에서는 오버핏이 어떤 원리로 발생하는지 알아보고, 오버핏을 완화하기 위한 대표적인 방법들을 몇 가지 소개했습니다. 이번에는 오버핏을 완화하는 좀 더 발전된 방법들을 알아보겠습니다.
오버핏이 안 일어나게 하는 단순하고 아주 효과적인 방법이 하나 있습니다. 데이터가 아주, 아주 많으면 됩니다. 데이터가 많을 수록 머신러닝이 똑똑해진다는 사실은 아주 보편적으로 확인됩니다. 대규모 언어모델(LLM; Large Language Model)이 급속도로 발전하게 된 핵심 요인 중의 하나도 더 많은 데이터를 사용하게 된 것이 한 몫을 합니다.
레이블과 데이터가 항상 많으면 좋겠지만, 언제나 그런 것은 아니죠. 레이블은 얼마 안 되지만 레이블이 없는 데이터를 활용해서 마치 데이터가 많아진 듯한 효과를 내고 싶을 때가 있습니다. 그럴 때 지난 번에도 다뤘던 세미 수퍼바이즈드 러닝을 활용하면 오버핏을 완화할 수 있습니다.
Temporal Ensembling for Semi-Supervised Learning
Laine and Alia, 2017 [arxiv]
삼식이는 휴머노이드 로봇입니다. 엑스레이 사진을 보고 결핵이 있는지 판단하는 공부를 매일같이 하고 있습니다. 유감스럽게도 레이블이 있는 엑스레이 사진이 무한정 많지는 않습니다. 몇 안 되는 사진의 레이블에 오버핏하지 않게 하기 위해 방법을 찾기로 했습니다. 엑스레이 사진을 구긴 다음에, 삼식이가 사진에 결핵이 있는지 없는지 판독합니다. 같은 사진을 새로 다시 구긴 다음에, 삼식이가 사진을 다시 판독합니다. 이 두 번의 판독은 같아야 마땅합니다. 엑스레이를 구겼다고 해서 없던 결핵이 생기는 것은 아니니까요. 이와 같이, 레이블이 없더라도, 판독결과가 일관되어야 한다는 제약조건을 걸어서 학습에 활용할 수 있습니다. 이것이 이 연구에서 제안하는 Π-모델의 핵심입니다. 아래 다이어그램에서 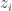


이 연구에서는 템포럴 앙상블링이라고 불리는 또 다른 방법도 제안합니다. 비유를 들어 설명하면 이렇습니다. 삼식이는 매일 한 번씩 전체 엑스레이 데이터를 학습합니다. 삼식이는 날마다 구겨진 엑스레이를 판독한 결과를 잘 보관해 놓습니다. 보관할 때에는 지금껏 판독했던 결과를 평균낸 것을 보관해 놓습니다. 삼식이는 매일 학습해나가고 있으므로 판독결과가 매일 조금씩 바뀝니다. 영순이를 찍은 엑스레이를 그저께 판독했을 때, 결핵이 있을 확률이 0.8이었고, 어제 판독했을 때, 결핵이 있을 확률이 0.7이었다고 해 봅시다. 그럼 삼식이가 영순이의 엑스레이에 대해서 평균적으로 0.75확률로 판정한 것입니다. 그럼 영순이가 결핵이 있는 건가요? 확실하게는 모릅니다. 영순이 엑스레이에는 레이블이 없어요. 하지만 삼식이가 오늘 판독한 결과가 그 전까지 판독의 평균인 0.75에서 아주 많이 벗어나지는 않는 편이 합리적입니다. 여러 판독을 종합한 값은 어느정도 믿을 만하다고 간주하는 것이지요. 이렇게 학습이 진행됨에 따라 판독한 결과가 너무 갑자기 바뀌지 않도록 제약을 가하는 것이 아래 다이어그램에서 설명하는 템포럴 앙상블링의 요점입니다.

여기서
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results
Tarvainen and Valpola, 2017 [arxiv]
삼식이는 로봇이므로 뇌 상태를 저장할 수 있습니다. 삼식이가 매일 조금씩 엑스레이 판독을 배워나가는 가운데, 매일매일의 뇌 상태를 저장해 놓습니다. 저장할 때에는 그동안 매일마다 달랐던 뇌 상태의 평균값을 저장합니다. 평균화된 뇌 상태는 매일매일 달라지는 삼식이의 뇌 상태보다 조금이라도 더 믿을 만하다고 간주하는 것입니다. 이렇게 평균낸 것을 민 티처라고 부르기로 합시다.
영순이를 찍은 엑스레이는 레이블이 없습니다. 민 티처가 영순이 엑스레이를 판정해서, 결핵이 있을 확률이 0.66로 산출했다고 합시다. 이 판정을 잠정적으로는 믿기로 합니다. 오늘의 삼식이는 영순이에게 결핵이 있을 확률이 0.66인 것으로 간주하고 배웁니다.
이것이 민 티처(mean teacher)의 핵심입니다. 앞서 다뤘던 템포럴 앙상블링에서는 판정 결과값을 평균하여 보관하는 것인데, 민 티처에서는 신경망의 가중치를 평균하여 보관하는 것이 핵심적인 차이점입니다.
Averaging Weights Leads to Wider Optima and Better Generalization
Izmailov et al., 2018 [arxiv]
삼식이가 학습을 해나가는 가운데, 매일 달라지는 뇌 상태의 평균을 저장해 둔다고 했습니다. 그게 더 믿을 만하다고 간주하고요. 그럼 그 평균해서 저장해 둔 삼식이 뇌를 최종 버전으로 간주하고 그냥 트레이닝을 종료시키면 되지 않을까요?
네 됩니다. 그게 민 티처 방법보다 더 구현하기 쉽습니다. 레이블이 없는 데이터를 생각할 필요도 없고, 신경망에 레이블 없는 데이터로 뭘 더 트레이닝시키는 과정도 없습니다. 그냥 평범한 머신러닝 방법대로 트레이닝 하다가, 후반부의 몇 개 버전의 모델을 골라서 평균내 버리는 것이므로, 추가로 들어가는 연산도 없고, 추가로 필요한 데이터도 없고, 코드도 매우 간단합니다. 그럼에도 테스트 정확도가 추가로 조금 더 상승합니다. 성적 향상을 거의 공짜로 즐기는 셈입니다. 이 방법은 SWA (stochastic weight average)라 부릅니다.
SWA는 파이토치에 기본 탑재되어 간단하게 켤 수 있습니다.
There are many consistent explanations of unlabeled data: Why you should average
Athiwarakun et al., 2019 [arxiv]
SWA는 트레이닝의 후반부에서 러닝 레이트가 오르락내리락 하는 사이클 방식으로 운용하고, 각 사이클마다 러닝 레이트가 가장 낮을 때의 모델을 취해서 평균냅니다. 아래 그림에서 녹색 부분입니다.

이 연구에서 제안하는 fast-SWA는 각 사이클마다 하나씩만 취하지 말고, 그냥 후반부의 모든 모델을 평균내는 방식입니다. 위 그림에서 빨간색 부분입니다.
싱거울만큼 간단한 변화인데, 이 방법이 SWA보다 더 빨리 평균화된 모델을 구해준다고 합니다. 왜냐면 평균을 낼 대상이 사이클마다 하나씩 나오던 것에서 사이클마다 여러 개 나오는 것으로 변했으니까요. 솔직히 대단한 발명까지는 아니지 싶습니다.
그래도 이 연구에서 의미있는 점은, 민 티처와 Π-모델에 fast-SWA를 추가해서 성능을 비교한 부분입니다. 아래 그림은 CIFAR-10에 fast-SWA를 추가했을 때 성능 향상이 있음을 보여줍니다. MT는 민 티처를 의미합니다.
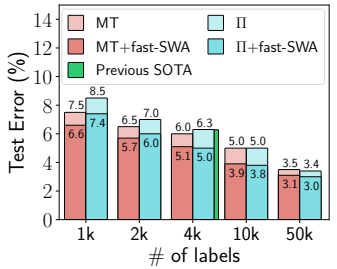
SWA, 혹은 fast-SWA는 거의 힘 안 들이고 쉽게 달성할 수 있는 보너스입니다. 안 할 이유가 없죠. 여러분도 한번 시도해 보시기 바랍니다.
온스퀘어에서는 소프트웨어 개발자를 상시 채용하고 있습니다.

One thought on “Overcoming Overfit (2) – From Mean Teacher to Stochastic Weight Average”