삼식이의 연어 통조림 공장에서는 컨베이어 벨트를 타고 가는 생선 중에 연어만 골라내고 싶습니다. 생선의 눈의 크기와 생선의 길이만 측정해서 연어인지 연어가 아닌지 맞추는 머신러닝 문제가 있다고 생각해 봅시다. 각 생선으로부터 측정된 값들은 아래처럼 2차원 도표에 그릴 수 있습니다.

연어는 원형, 연어 아닌 것은 삼각형으로 표시합시다. 여기서 회색인 것들만 트레이닝에 사용하고 빨간 색으로 된 것은 숨겨놨다가 트레이닝이 끝난 다음, 머신러닝 모델의 성적을 측정하는 데 쓰기로 합시다. 회색 점들을 트레이닝 셋, 빨간 점들을 테스트 셋이라 부릅니다.
먼저 

어떤 생선




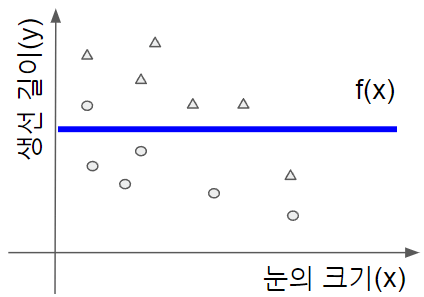
파란색 선의 아랫부분이면 연어인 것으로 예측하는 것입니다. 보다시피 0차 함수로는 어떻게 해도 모든 데이터에 완전히 맞출 수는 없습니다. 파라미터가
이제 데이터를 1차 함수에 맞춰 봅시다. 1차 함수는 아래처럼 표현됩니다.

파라미터가 

적당히 잘 맞아 보입니다. 테스트용 데이터도 잘 맞았는지 살펴봅시다.
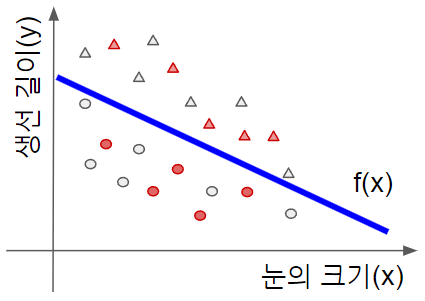
빨간 색으로 표시된 테스트용 데이터도 완벽하게 잘 맞았네요. 원래 이 예제는 1차원 함수에 적합하도록 일부러 만든 것이긴 하지만요 😊😊😊
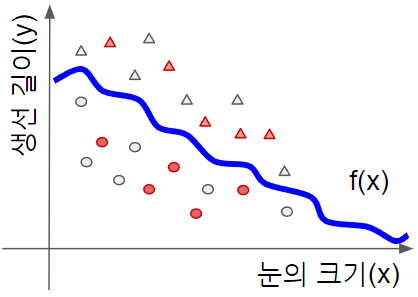
파라미터를 더 늘려봅시다. 아래와 같은

파라미터의 갯수가 많아진 만큼, 복잡한 형태의 곡선을 표현할 수 있습니다. 아래처럼요.

동그라미는 모두 선 아래쪽에 있고 삼각형은 모두 선 위쪽에 있으니까 분류가 잘 되었죠? 그런데 뭔가 찜찜하지요? 테스트용 데이터를 넣어서 얼마나 맞았는지 볼까요?

10개의 빨간 것들 중에 5개가 잘못 분류되었습니다. 파라미터를 늘렸더니 트레이닝용 데이터에만 잘 맞고 테스트용 데이터에는 맞지 않는 경우가 생겼습니다. 이런 현상을 높은 베리언스(high variance)라고 합니다.
머신러닝 트레이닝을 할 때, 테스트 로스는 지속적으로 감소하는 가운데 트레이닝 로스가 점점 높아지는 현상은 아주 보편적으로 일어납니다. 이것을 오버핏(overfit)이라고도 부릅니다.
파라미터가 많으면 오버핏이 발생할 수 있습니다. 그런데, 반드시 꼭 그렇기만 한 것은 아닙니다. 파라미터가 많아도 베리언스가 높지 않을 수 있어요. 아래 그림을 보세요.
위 예제는 이해를 돕기 위해 일부러 단순화시켰기 때문에 파라미터가 많으면서도 오버핏하지 않는 함수가 구하기 쉬워 보일 지도 모르겠습니다. 하지만 실제의 데이터들은 아주 고차원이고, 머신러닝 모델의 파라미터도 수백만~수천억개에 이릅니다. 어디에 그릴 수도 없고 머리로 상상하기도 불가능한 세계입니다.
이런 환경에서 오버핏을 막는 방법들 중 아주 대표적인 것들을 몇 가지 소개하겠습니다.
얼리 스토핑 (early stopping)
트레이닝 초반에는 테스트 셋(위의 예에서 빨간색 점)에도 트레이닝 셋(위의 예에서 회색 점)에도 잘 맞지 않습니다. 그러다 점차 트레이닝이 진행되면서 머신러닝 모델이 트레이닝 셋에 맞춰가게 되는데, 이에 따라 테스트용 데이터에도 맞아가게 됩니다. 아래 차트가 시간에 따라 머신러닝 모델이 데이터에 맞아가는 추이를 전형적으로 보여줍니다.

트레이닝이 진행되다 어느 순간부터는 테스트 셋에 잘 맞지 않게 되는 때가 오는데, 그 때가 오기 직전에 트레이닝을 종료하는 겁니다. 싱겁죠?
웨이트 디케이 (weight decay)
파라미터 값들이 커지지 않도록 다음과 같이 머신러닝의 최적화 목표를 추가해 줍니다.

앞서 들었던 예제에서 오버핏이 일어나는 경우를 생각해 보세요 ([그림 5] 요동치는 파란 선). 파라미터의 값들이 크면 클 수록 곡선이 요동치기 마련입니다. 파란 선이 얌전하게 이어지려면 전반적으로 값들이 작아야 합니다. 웨이트 디케이는 선이 요동치지 않도록 가장 명시적으로 제약조건을 주는 방법입니다.
드롭아웃 (dropout)
트레이닝 과정에서 파라미터
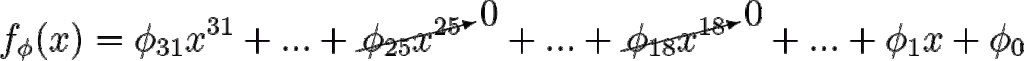
위와 같이 랜덤하게 몇몇 항을 0으로 할당해 버리는 것입니다. 그럼에도 불구하고 전체적으로 정상 작동하도록 트레이닝 목표가 주어지는 것이지요.
레이블 스무딩 (label smoothing)
연어인지 아닌지 판단하는 앞서의 예로 돌아갑시다. 레이블은 연어인 경우 [1.0, 0.0], 연어가 아닌 경우 [0.0, 1.0]으로 주어집니다. 이 때 첫 번째 숫자는 연어일 확률, 두 번째 숫자는 연어가 아닐 확률로 해석할 수 있습니다. 그런데 세상에 100%라는 게 없잖아요? 약간의 절충을 가해서, 연어인 경우 [0.99, 0.01], 연어가 아닌 경우 [0.01, 0.99]이런 식으로 레이블을 공급하는 방법이 레이블 스무딩입니다. 이렇게 스무딩이 들어가는 레이블이 공급되면, 머신러닝이 이미 잘 예측하고 있는 데이터에 대해서는 더이상 학습을 하지 않게 됩니다 (왜 그런지 분석하려면 약간 수학적인 전개가 등장하지만, 일단 넘어가겠습니다). 쉬운 문제는 놔두고 어려운 문제에 집중하는 원리로 “요동치는 파란 선”이 덜 생기게 되는 것입니다.
온스퀘어에서는 소프트웨어 개발자를 상시 채용하고 있습니다.
오버핏은 머신러닝에서 반드시 발생하는 현상이고, 그만큼 중요한 문제입니다. 이 때문에 오버핏을 완화하기 위한 방법도 대단히 많이 연구되어 있습니다. 다음 글에서는 오버핏을 완화하는 좀 더 진보된 방법을 다뤄 보겠습니다.
다음 글: Overcoming Overfit (2) – From Mean Teacher to Stochastic Weight Average
참고 자료

One thought on “Overcoming Overfit (1) – Weight decay and label smoothing”