특별한 사정이 없는 경우에는 머신러닝에서 사용하는 수들은 float32자료형으로 저장합니다. 적당한 정밀도를 제공하고, GPU에서도 가장 일반적으로 처리해주는 자료형이기 때문입니다. float32는 이름에서도 나타나듯이, 32비트 자료형입니다. 수 하나를 표현하기 위해 4바이트를 사용합니다. 한편, GPU는 16비트 자료형인 float16도 처리할 수 있습니다. 이것은 메모리를 절반만 차지하기 때문에, 용량이 큰 인공신경망을 처리하는데 유리합니다. 게다가 float16은 속도가 더 빠르다는 장점이 있습니다. NVIDIA에 따르면, float16으로 연산하면 연산속도가 최대 4.5배 빨라진다고 합니다.
그럼 그냥 float16만 쓰면 되지 왜, “특별한 사정이 없는 경우” float32를 기본으로 쓸까요? 수를 컴퓨터로 표현하는 데에는 한계가 있기 때문입니다. 용량을 절약해서 표현할 수록 그 한계가 금방 나타납니다. 구체적으로 어떤 한계인지 알아봅시다. float16은 2진수로 저장될 때 아래와 같이 세 가지 부분으로 구성됩니다.

보라색 부분은 음수인지 양수인지 표시하는 부분이고(1또는 -1을 나타냄), 녹색 부분은, 표현하려는 수가 2의 몇제곱에 가까운지를 나태내는 부분이고(
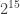
이 자료형을 머신러닝에 사용할 때, 구체적으로 어떤 부분 때문에 한계가 발생하는 것일까요?

float16은 아주 작은 수를 표현하지 못하기 때문 아닌가요?

그렇지는 않습니다. float16도 머신러닝에 필요한 만큼은 작은 수를 표현할 수 있습니다. 무려 1천만분의 1까지 표현할 수 있습니다.
float16이 문제가 되는 때는, 아주 작은 수와 큰 수를 더할 때 발생합니다. 무슨 뜻인지 좀 더 자세히 알아보겠습니다.
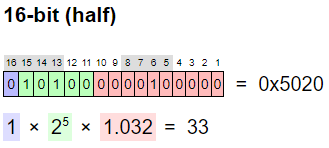
위 그림은 33을 float16으로 표현한 것입니다.
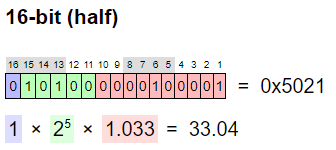
33보다 큰 수 중에 가장 작은 것은 33.04입니다. 33과 33.04사이의 수는 float16으로는 표현할 수 없습니다.

위 그림은 100만분의 3을 float16으로 표현한 것인데요. 만약 0.000003과 33을 더하면 어떻게 될까요? 33.000003이어야 마땅하겠지만, 앞서 말한 것처럼 float16으로는 표현할 수 없어서, 가장 가까운 수인 33이 나옵니다. float16에서는 33 + 0.000003 = 33 입니다.

반면, float32에서는 33.000003을 표현할 수 있습니다. 그래서 큰 수와 작은 수를 더할 때에는 float32를 써야 합니다.
덧셈 말고 곱셈을 할 때에도 같은 문제가 생기나요?
좋은 질문입니다. 두 수를 곱할 때 어떤 일이 일어나는지 봅시다. 


여기서 a와c는 덧셈을 하고 있습니다. 따라서 x가 큰 수(a가 양수)이고 y가 작은 수(c가 음수)라고 하더라도, 둘을 곱하는 경우에는 정밀도 때문에 큰 문제가 생기지는 않습니다.
머신러닝에서 곱셈을 많이 쓰는 때는 매트릭스 곱을 할 때입니다. 매트릭스 곱셈 안에는 실수 곱셈 연산이 여러 번 들어갑니다. 이 때 float16을 사용하면 메모리를 절약하면서 연산속도도 빠르게 할 수 있습니다. Dall-E에서는 리지듀얼 블럭에서 신경망의 가중값을 곱하기 직전에 float16으로 변환하고, 직후에 다시 float32로 변환하는 것을 볼 수 있습니다. 아래 그림을 보세요.

위 그림의 위아래에는 
float32를 사용해야 하는 또 다른 중요한 곳은, SGD나 Adam등을 사용해서 가중값을 최적화하는 부분입니다. SGD는 보통 아래와 같이 표현되는데요,

여기서 두 번째 항 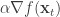
온스퀘어에서는 소프트웨어 개발자를 상시 채용하고 있습니다.
참고자료
