Semi or unsupervised Learning
삼식이는 연어를 통조림으로 만드는 회사에 근무합니다. 공급받은 연어가 컨베이어 벨트에서 줄지어 생산라인으로 들어가는데, 가끔 연어가 아닌 생선이 들어오기도 합니다. 컨베이어 벨트 위에 카메라를 달고, 들어오는 생선을 촬영해서 연어인지 아닌지 판단하는 컴퓨터 시스템을 만들려고 합니다. 이 과제는 머신러닝을 이용해서 분류해 보기로 결심했습니다. 컨베이어 벨트로 들어오는 생선 사진은 얼마든지 많이 구할 수 있습니다. 문제는 이게 연어인지 아닌지 알려주는 레이블을 만드는 것입니다. 삼식이는 연어 전문가도 아닙니다. 현장에서 연어를 잘 알아보는 분을 모셔다가 500개 정도 직접 레이블을 만들다 보니 벌써 지쳐갑니다. 다른 방법은 없는지 궁금해졌습니다. 레이블이 없는 데이터는 얼마든지 구할 수 있는데, 이걸 트레이닝에 활용해서 정확도를 높이는 방법이 없을까요? 이런 문제의식에서 나온 것이 세미 수퍼바이즈드 러닝입니다.
Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks
Lee, 2013 [link to PDF @ Google Scholar]
레이블이 없는 데이터에 수도(pseudo 가짜) 레이블을 줘가면서 트레이닝 하는 방법입니다. 수도 레이블은 지금까지 트레이닝하던 모델이 예측한 클래스를 적용합니다. 트레이닝이 덜 된 모델이니까 연어가 맞는데도 아니라고 잘못 예측할 수도 있겠죠? 이런 잘못된 수도 레이블을 트레이닝에 사용하면 결과가 나빠질 수가 있습니다. 이런 현상을 확증편향(confirmation bias)이라고 합니다. 저자들도 이걸 알고 있고, 이 문제를 완화하는 방법을 마련했습니다. 로스(loss) 함수를 봅시다:

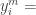

위 식에서 함수 

초창기에는 수도 레이블을 로스에 전혀 반영하지 않다가, 


공부를 처음 시작할 때에는 정답지가 있는 문제집만 풀다가, 어느정도 공부를 했을 때부터 정답지가 분실된 문제집도 풀어보는 것으로 비유를 들 수 있겠습니다. 이러면 확증편향에 빠지는 위험보다 레이블이 없는 더 많은 문제를 풀어서 얻는 이득이 더 많아진다고 할 수 있습니다.
Distilling the knowledge in a neural network
Hinton et al., 2015 [arxiv]
이 연구에서 다루는 문제는 세미 수퍼바이즈드 러닝은 아닙니다. 하지만 뒤에서 소개할 연구와 깊은 관련이 있어서 언급합니다.
다시 삼식이의 식품공장으로 갑니다. 생선이 연어인지 아닌지 판단한 레이블을 충분히 많이 모았다고 생각해 봅시다. 이제 연어를 분류하는 뉴럴넷을 일단 훈련을 시킵니다. 그렇게 산출된 뉴럴넷을 교사(teacher)라고 부릅시다. 그리고 또다른 뉴럴넷인 학생(student)을 훈련시킵니다. 학생 뉴럴넷은 원래의 레이블이 아니라 교사가 내린 판단을 레이블로 사용해서 학습합니다. 교사의 판단은 하드 레이블이 아니라 소프트 레이블로 적용합니다. 연어가 맞으면 1 틀리면 0으로 레이블 붙이는 것이 하드 레이블이고, 그 사이의 0.8이나 0.4같은 레이블 값도 허용하는 것이 소프트 레이블입니다. 아주 확실히 연어처럼 보이는 것과, 연어인 것 같긴 한데 왠지 자신이 없는 것도 있을 것입니다. 소프트 레이블링은 이런 차이를 트레이닝에 반영할 수 있습니다.
이 연구의 저자가 발견한 중요한 인사이트는, 이렇게 훈련된 학생은 교사보다 과제를 일반화하는 데 더 뛰어나면서, 네트웍의 크기가 작아도 성능에 문제가 없다는 것입니다. 머신러닝에 흔히 사용하는 레이블은 하드 레이블인데, 교사가 소프트 레이블을 제공하기 때문에 이런 장점이 생기는 것 같습니다.
교사가 제공하는 레이블의 부드러운 정도(softness)는 아래 식으로 조절할 수 있습니다:

T=1인 경우는 일반적인 소프트맥스입니다. T가 1보다 작아지면 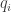
Self-training with Noisy Student improves ImageNet classification
Xie et al., 2019 [arxiv]
수도 레이블[Lee, 2013] 에서의 확증편향은 아무래도 신경이 쓰입니다. 연어가 아닌데 연어라고 결론짓고 그걸 학습한다고 생각하면 껄끄럽죠. 이번 연구에서는 앞선 [Hinton et al., 2015] 에서의 교사-학생 관계와 수도 레이블을 동시에 응용합니다. 앞의 두 연구를 이해한다면 아래 그림만 봐도 이번 연구에서 사용한 방법의 흐름을 금방 이해할 수 있습니다.

여기서 중요한 점은 교사에 노이즈를 넣는다는 것과, 학생의 네트웍 크기는 교사보다 작지 않다는 것입니다. 학생이 다시 교사가 되어야 하는데 네트웍 크기를 작게 해버리면 다음 세대의 학생은 더 작아지게 되고, 얼핏 생각해도 바람직하지 않지요. 일부러 노이즈를 넣음으로써, 확증 편향에 의한 오류를 어느정도 극복하게 합니다. 일반화를 더 잘 하게 되는 효과도 있을 것입니다. 아래의 알고리즘 스케치를 보고 갑시다:

Fixmatch: Simplifying semi-supervised learning with consistency and confidence
Shon et al., 2020 [arxiv]
삼식이한테 선글라스를 씌워주고 저 생선이 뭔지 물어봅니다. 연어라고 대답합니다. 이번엔 더러워서 잘 안 보이는 안경을 씌워주고 아까 그 생선을 가리키며 뭐냐고 물어봅니다. 이번엔 참치라고 대답합니다. 삼식이가 대답을 잘못하고 있다는 것은 확실해졌죠. 안경을 바꿔도 같은 생선은 같은 답을 해야 된다고 훈련시킨다면 이것이 Fixmatch입니다. 방금 본 생선의 실제 레이블은 없어도 됩니다. 응답의 일관성이 훈련의 요점입니다. 아래 그림을 봅시다:

어째서 이 방법이 세미 수퍼바이즈드 러닝으로 효과가 좋은지는 아주 자명하게 이해되지는 않습니다. 저 나름의 해석은 이렇습니다. 레이블이 없는 데이터는 그것이 영상이든 음성이든, 컴퓨터에서는 정수의 배열로 나타내집니다. 이것은 표현방법에 따라 고차원 공간상의 하나의 점으로 표시할 수도 있습니다. 고차원 공간은 화면에 그리기가 까다로우니 편의상 과감히 2차원까지만 표시해보겠습니다.

이 전체 공간


이제 어떤 말 영상 


A Simple Framework for Contrastive Learning of Visual Representations
Chen et al., 2020 [arxiv]
삼식이는 사진속 생선이 연어인지 아닌지에 대해 관심이 있습니다. 먼저, 생선 사진으로부터 알 수 있는 속성들을 나열해 보았습니다. 생선의 길이, 색상, 눈의 크기, 길이와 폭의 비율 등등… 이 중 눈의 크기와 생선의 길이를 선택해서 2차원 차트에다 각 생선 사진들을 점으로 표시해 봤습니다. 그랬더니 연어 사진들은 모두 차트의 한쪽에 모여있는 것을 발견했습니다. 빙고!

(예를 든 것일 뿐 이것이 연어를 식별하는데 실제로 유용한 것은 아닙니다.)
이처럼 원본 데이터를 차트 위에 표현했을 때, 서로 유사한 것끼리 모여 있고, 유사하지 않은 것들은 멀리 떨어져 있다면 분류가 수월해 집니다. 문제는 차트에서 가로축, 세로축을 담당하는 알맞은 척도를 어떻게 찾느냐겠죠. 그것을 머신 러닝을 이용해서 찾아봅시다.
방금 예를 든 것을 힌트로 삼아 형식적으로 정리해 보겠습니다. 데이터D를 어떤 저차원의 임베딩 공간z로 보내는 함수f: D → z가 있을 때, 데이터a,b가 같은 종류이면 f(a)와 f(b)가 가까운 곳에 위치하게 되는 z와 f를 구하는 것을 컨트라스티브 러닝(contrastive learning)이라고 합니다.
위에서 “같은 종류”와 “가깝다”는 것은 구체적으로 뭔지 알아봅시다. 이 연구에서 제안하는 방법, SimCLR은 레이블이 없는 데이터 
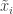
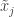

SimCLR은 앞에서 설명한 Fixmatch [Shon et al., 2020]와 *매우* 비슷합니다. 하나의 데이터에 대해서 두 가지 어구먼테이션이 등장하고, 이 둘 간의 공통점을 이용합니다. 조금 다른 점은 Fixmatch는 세미 수퍼바이즈드 러닝을 염두에 뒀다는 점입니다. 이땐 레이블에 사용할 클래스 목록(예: 개, 고양이, 말)이 존재합니다. 이 클래스 목록에 있는 것 중 하나를 맞추는 것으로 문제가 정의되어 있습니다. 반면, SimCLR은 레이블도 클래스 목록도 없이 데이터만 보고 거기에 내재된 관계를 학습하는 방법입니다. 이를 언수퍼바이즈드 러닝(unsupervised learning)이라고 합니다. 데이터 하나에 대해서 자기 자신의 변형들끼리의 관계를 학습하므로 셀프 수퍼바이즈드 러닝(self-supervised learning)이라고도 합니다.

개의 품종을 모르는 사람에게도, 위의 개들이 다 같은 품종이라는 것은 자명합니다.
SimCLR의 로스는 아래처럼 정의됩니다:

여기서𝜏는 [Hinton et al., 2015]에서 다뤘던, 부드러운 정도를 제어하는 파라미터입니다.
Supervised Contrastive Learning
Khosla et al., NIPS 2020 [arxiv]
앞선 SimCLR [Chen et al., 2020]은 레이블이 필요 없다고 했습니다. 레이블이 있는 경우에도 레이블을 사용 안 해버리면 아깝잖아요? 그래서 이 연구에서는 레이블이 같은 경우는 임베딩 공간(아래 그림에서 원으로 표시)에서도 가깝도록 로스를 설정해 줍니다. 핵심은 이게 다에요. 진짜로.

확대해서 보시면 편합니다
Meta Pseudo Labels
Pham et al., 2021 [arxiv]
훌륭한 교사는 학생의 수준에 맞춘 강의를 합니다. 이 연구에서는 학생이 가장 올바르게 배울 수 있도록 교사 네트워크가 백프로퍼게이트됩니다!

수도 레이블에서 하는 일을 되새겨봅시다. (지금부터 정리하는 내용은 [Lee 2013]이나 [Xie et al. 2019]과는 미묘하게 다릅니다.)

교사

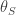


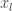

모범생 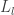


여기에 부합하게 교사를 백프로퍼게이트하는 미분식 유도는 거의 불가능합니다. 때문에, 저자들은 근사법을 시도하는데, 결론적으로는 학생과 교사가 한 스텝씩 SGD를 번갈아가며 합니다:

위 식이 이해 안 되는 분, 걱정 마세요. 정상입니다. 특히 교사를 업데이트하는 부분은 미분을 전개하기가 무척 까다롭습니다. 논문에는 부록A에 실려 있는데, 야심있는 분들은 도전해 보세요!
Semantic Segmentation with Generative Models: Semi-Supervised Learning and Strong Out-of-Domain Generalization
Li et al., CVPR 2021 [arxiv]
이미지 세그먼테이션용 레이블링은 고된 작업입니다. 얼굴에서 정교하게 눈코입머리눈썹을 세그먼트한다고 생각해 봅시다. 트레이닝용 레이블이 10만개쯤 필요하다면 노동의 규모가 굉장할 겁니다. 의료영상처럼 전문지식이 있는 레이블러가 필요한 경우엔 인건비가 더 올라가겠죠. 이 연구에서는 GAN으로 그럴듯한 세그먼테이션과 이미지를 쌍으로 생성해 줍니다:

CoCa: Contrastive Captioners are Image-Text Foundation Models
Yu et al., 2022 [arxiv]
곧 업데이트 예정
Featured image: Photo by Jocelyn Morales on Unsplash

식품업계에서 근무하고 있는 입장에서 첫 예시가 이해가 잘 되네요. 근데 실제 식품업계에서 AI를 도입하려면 시간이 좀 걸릴 것 같습니다. 저런 역할을 하는 기계는 출시된다 해도 아직 좀 많이 비싸지 않을까요. 이젠 거의 의무적으로 적용해야 하는 HACCP조차도 금전적인 이유 때문에 포기하는 사업체들이 있는걸로 아는데요.
LikeLike