StyleGAN 논문을 읽다 이해가 안 된다는 분 어서 오십시오. GAN분야를 위주로 공부했던 분들은 StyleGAN의 구조에서 AdaIN이 어떤 역할을 하는지 이해하기 어려웠을 수 있습니다. 식은 간단하지만 이게 스타일이랑 어째서 연관이 있는 것인지 논문에는 구구절절 써있지는 않기 때문입니다. StyleGAN의 작동원리를 이해하기 위해서는 스타일 트랜스퍼 (전이)에 대한 이해가 수반되어야 합니다. 이번 글에서는 StyleGAN에 숨어 있는 스타일 전이 방법이 어떻게 발전해왔는지 알아보겠습니다.
Image Style Transfer Using Convolutional Neural Networks
Gatys et al., CVPR 2016 [PDF]

여러 말이 필요 없습니다. 위의 그림이 스타일 전이가 뭔지 전부 설명하고 있습니다. 스타일 전이는 기계학습이 지금처럼 유행하기 전에도 있었던 방법입니다. 하지만 이 연구에서는 기계학습에 사용되는 인공신경망을 이용해서 스타일 전이를 시도해서 좀 더 유연하고 좋은 품질의 결과를 얻었습니다.
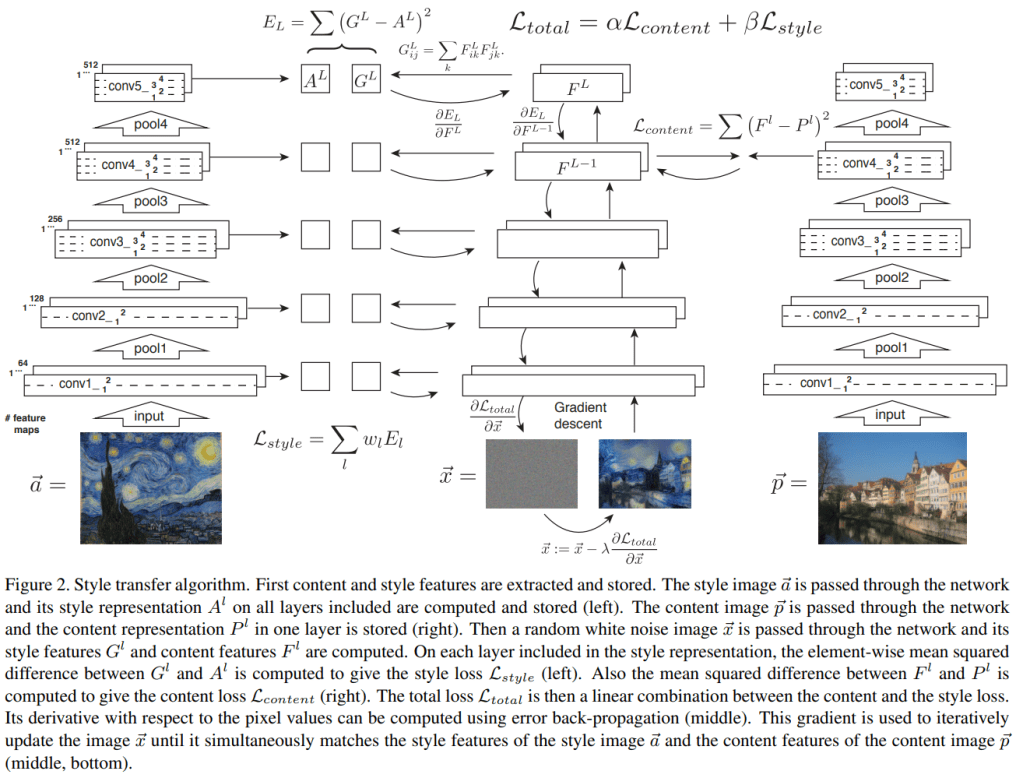
그림이 좀 복잡하지만, 안심하세요. 전부 다 설명하지 않을 겁니다. 전체의 흐름을 파악하는 데에 꼭 필요한 부분만 짚어보겠습니다. 여기서는 영상 인식에 활용하는 VGG네트웍을 이용합니다. 트레이닝이 이미 완료된 것을 사용만 하고 추가로 백 프로퍼게이트는 하지 않습니다. 위 그림에서는 아래로부터 위를 향해 데이터가 흐르는 것으로 묘사되는데, 그림의 각 층은 VGG네트웍의 각 레이어를 뜻합니다. 위로 갈수록 원본 영상으로부터 더 추상적인 특징을 추출해갑니다. (VGG에 대해 이해한다고 여기고 상세하게는 다루지 않겠습니다)
스타일 이미지로부터는 영상의 전반적인 통계를 추출합니다. 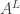
컨텐트 이미지에서는 사물들의 위치를 중요시하게 됩니다. 예컨대 위의 예에 있는 컨텐트 이미지에서 종탑의 위치를 옮긴다면, 결과물에서도 종탑의 위치가 정확하게 따라 옮겨가야 할 것입니다. 이를 위해서는 VGG가 산출하는 각 레이어의 값 

결과물 이미지 
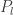

하지만 여기서는 데이터 x를 업데이트하는 것으로 백프로퍼게이션을 수행합니다. 앞서 말했듯 VGG인공신경망의 가중값은 변경하지 않습니다. 이로써 컨텐트와 스타일 이미지를 동시에 따르는 결과물 x가 그라디언트 디슨트 최적화 과정을 통해 점차 완성되는 것입니다.
이 방법의 대표적인 한계점은 연산 시간입니다. 컨텐트와 스타일 이미지가 짝지어 입력으로 주어지면 그 때마다 그라디언트 디슨트를 수행해야 합니다. 결과물 이미지 한 장을 얻기 위해서 상당한 시간을 소요해야 하는 셈인데, 후속 연구들은 이 시간을 단축하는 데 집중합니다. 그리고 이 과정에서 스타일 전이의 본질에 대해서 다른 각도에서 생각해보게 됩니다.
Perceptual Losses for Real-Time Style Transfer and Super-Resolution
Johnson et al. 2016 [arxiv]
앞서 소개한 [Gatys et al., 2016]에서는 신경망의 가중값 w을 트레이닝하는 것이 아니라, 데이터 x를 트레이닝한다고 했었습니다. 이번에 소개하는 방법은, 일반적인 인공신경망 최적화 방법대로 가중값 w을 트레이닝합니다. 이렇게 트레이닝된 신경망 
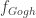


트레이닝을 어떻게 하는지 봅시다. 스타일 목표 (예컨대 고흐 그림)을 하나 정합니다 (



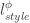
이렇게 하면, 스타일의 갯수만큼 신경망
A Learned Representation for Artistic Style
Dumoulin et al., 2017 [arxiv]
스타일 트랜스퍼용 모바일 앱을 만든다고 생각해 봅시다. 앞서 소개한 [Johnson et al., 2016] 방법을 사용하면 제공하는 스타일의 갯수만큼 신경망 가중값을 저장해 둬야 합니다. 어림잡아 스타일당 10MB정도의 용량을 차지한다고 가정하면, 10가지 스타일만 제공해도 100MB를 차지하게 됩니다. 고흐 스타일 신경망과 칸딘스키 스타일 신경망이 있다고 해 봅시다. 이 둘은 각자 고유한 부분이 물론 있겠지만, 공유될 수 있는 부분도 있지 않을까요? 신경망을 고유한 부분과 공유하는 부분이 있도록 만들어서 여러 스타일을 한꺼번에 처리하면 파라미터의 수를 절약할 수 있지 않을까요? 이 부분을 해결하기 위해, 스타일이란 무엇인가에 대해 저자들은 독창적인 발상을 하게 됩니다.
저자들은 스타일을 나타낼 때 중요한 요소는 신경망의 각 레이어에서 특징값들의 평균과 표준편차라고 봤습니다. 다시 말해, 특징값들의 평균과 표준편차만 스타일별로 각각 저장하고, 다른 가중값들은 모든 스타일에 공통으로 처리할 수 있을 것으로 봤습니다. 저는 이 내용을 읽었을 때 바로 “아 그럴만 하구나”라고 직관적으로 와닿지는 않습니다. 거꾸로 “이들은 어쩌다 그런게 가능하다는걸 알았나?” 하는 의문이 들었는데, 여기에 대해서 저자들이 논문에 해설해둔 것이 있지만, 결국 어떤 심오한 통찰이 필요했을 것 같습니다. 어쨌거나 정보의 흐름을 도식화하면 아래처럼 그릴 수 있습니다:
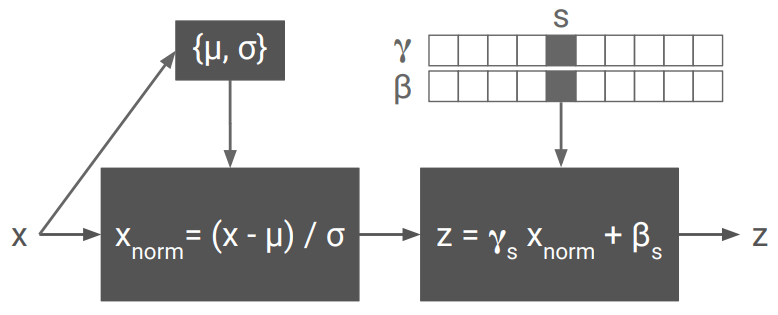
신경망의 각 레이어에서, 각 특징값(feature, 또는 채널이라고도 표현하는 그것입니다)별로 평균과 표준편차가 하나씩 저장되어서 하나의 스타일을 정의합니다. 달리 말하면, 인스턴스 노멀라이제이션을 먼저 한 다음 평균과 표준편차를 개별 스타일용 값으로 조정하는 것입니다. 예컨대 가로로 10픽셀이고 세로로 5픽셀이면, 총 50개의 숫자에 대해서 특정 스타일용 평균(위 그림에서 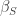
논문의 부록에 모델의 세부 명세가 공개돼 있어서, 몇 개의 파라미터가 스타일 하나를 위해 할당되는지 세어 봤습니다. 평균과 표준편차, 이 두 개의 파라미터를 저장하는 데 있어서, 128개의 피처 채널로 이루어진 컨볼루션 레이어 2개가 하나의 리지듀얼 블럭을 형성하는데, 이 블럭이 5개 쌓여 있습니다.
(5 residuals) × (128 feature maps) × (2 convs) × (1 mean + 1 std) = 2,560 params
따라서 대략 3천개 안쪽의 파라미터를 추가하면 스타일 하나를 추가할 수 있습니다. 앞서서 소개한 [Johnson et al., 2016]에서는 스타일 하나당 신경망 하나가 통으로 필요했던 것에 비하면 큰 발전입니다. 게다가, 이 추가 파라미터들은 스타일들을 인터폴레이션 하기에도 용이합니다:

용량에 큰 부담 없이 스타일을 추가할 수 있게 되었으니, 이만하면 문제가 뚜렷하게 개선됐다고 볼 수 있습니다. 논문에서는 16가지의 스타일을 한 번에 트레이닝해서 시연하고 있습니다. 하지만 몇 가지의 스타일을 사용할 것인지를 트레이닝 전에 정해야만 합니다. 이 기술로 스타일 전이 앱을 제작한다면, 앱 제작자가 지정한 십수 가지의 스타일 중에서 사용자가 선택할 수는 있겠지만, 사용자가 자신이 만든 이미지를 스타일로 등록할 수는 없습니다.
게다가, 부담이 적다고는 해도 스타일을 무한정 늘릴 수는 없습니다. 이에 따라서 트레이너블 파라미터가 늘어나기 때문입니다. 제공하는 스타일의 갯수의 제약에서 완전히 벗어나는 방법은 없을까요?
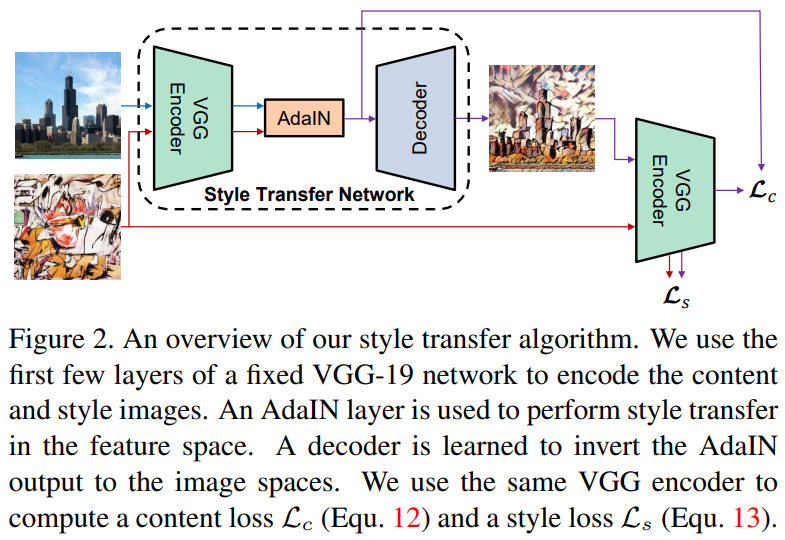
Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization
Huang and Belongie, 2017 [arxiv]
스타일에 대한 새로운 발상이 또 등장합니다. 이 방법에 의하면 신경망의 파라미터 수가 고정된 채로 스타일을 무한정 사용할 수 있습니다. 임의의 스타일과 컨텐트 이미지 쌍을 입력으로 트레이닝하게 되며, 트레이닝이 끝나면 얼마든지 임의의 스타일 이미지와 컨텐트 이미지를 받아서 결과물을 빠르게 생성할 수 있습니다.
어떤 방법이길래 이게 가능해졌을까요? 직전의 [Dumoulin et al., 2017]에서 평균과 표준편차를 트레이너블 파라미터로 설계했다고 했습니다. 이게 최적화 과정에서 정해지도록 허락하는 것이 아니라, 적절한 값으로 미리 정해서 거꾸로 뉴럴넷에 제공해 버리면 어떨까요? 그럼 뭐가 적절한 걸까요? 저자들은 스타일 이미지 


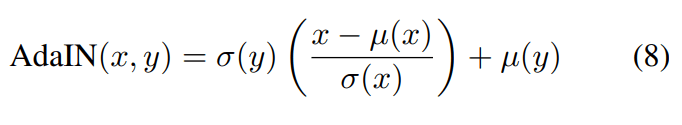
여기서
여전히 로스 

중간 요점정리
지금까지 스타일 전이 방법에서 트레이닝 전략이 어떻게 바뀌었는지 살펴봤습니다. 처음 소개한 연구 [Gatys et al., 2016]에서 제시한 뼈대에 해당하는 두 가지 아이디어들은 이후의 연구에서도 변함없이 쓰이고 있습니다: (1) 이미 트레이닝된 VGG를 사용해서 중간 레이어의 특징값을 이용한다. (2) 컨텐트 이미지와 스타일 이미지로부터 각각 고유한 로스를 구축한다.
이후의 연구들은 미리 트레이닝한 네트웍으로 빠르게 결과물을 얻는 데 초점을 두었습니다. 조금 더 생각하기 쉬운 방법이 먼저 등장하고, 스타일에 관한 과감한 통찰이 가미되면서 제약이 조금씩 사라져갔습니다. 마지막으로 등장한 AdaIN은 방법 자체는 단순하지만, 지금까지 소개했던 발전의 궤적을 모른다면, 작동원리가 직관적이지 않아서 다소 의아하게 보일 수 있습니다. 이제 최종목표인 StyleGAN으로 가겠습니다. AdaIN을 이해하면 StyleGAN을 아주 쉽게 이해할 수 있습니다.
A Style-Based Generator Architecture for Generative Adversarial Networks
Karras et al., CVPR 2019 [arxiv]
GAN의 기본개념에 대해서는 알고 있다고 생각하고 진행하겠습니다. Progressive GAN이라는 고해상도 이미지 트레이닝 방법이 있습니다. 아래 그림의 왼쪽 (a) Traditional에 해당하는 방법으로, 저해상도 이미지로부터 점차 해상도를 높여가며 이미지를 생성하는 방법입니다. StyleGAN도 마찬가지로 저해상도부터 시작하여 해상도를 높입니다. 이 때 AdaIN이 매 레이어마다 설치되었고, 스타일의 평균과 표준편차 역할을 할 정보가 w로부터 공급됩니다. 아래 그림과 그에 수반한 캡션을 찬찬히 보시기 바랍니다.

위 그림에서 A라고 표시된 상자가 스타일을 나타냅니다. 이 부분이 이번엔 다시 트레이너블 파라미터가 되었습니다. B 상자는 노이즈를 공급하는데, 결과물 텍스처의 다양성을 표현하는 목적과, 레이턴트 스페이스를 안정화시키는 목적이 모두 있을 것 같습니다 (오토인코더와 베리에이셔널 오토인코더의 차이를 생각해 봅시다). AdaIN덕분에 세밀한 스케일에서부터 거시적인 스케일까지, 각 스케일별로 스타일을 지정할 수 있게 되었습니다. Figure 3에서 보여지는 스타일 전이는 이같은 배경에서 가능해진 것입니다 (Figure 3는 여기에 옮겨 싣지 않았습니다). 여기서는 VGG가 완전히 빠진 것도 생각해볼만 합니다. 뼈대로 하고 있는 Progressive GAN의 영상 생성 능력이 충분하기 때문에 VGG의 특징 추출 능력이 불필요했던 것 같습니다.
스타일 전이는 GAN과는 별개로 여겨진 연구 분야였는데, StyleGAN을 통해서 서로 결합되어서 탁월한 성과를 내는 것을 보면서, 분야를 넘나드는 시각이 중요하다는 것을 다시한번 깨우칩니다.
Analyzing and Improving the Image Quality of StyleGAN
Karras et al., 2020 [arxiv]
StyleGAN으로 만들어진 결과물들은 자세히 보면 특이한 자국(artifact)을 볼 수 있습니다. StyleGAN의 모든 결과물에서 나오는데, 레이턴트 스페이스에서 더 확연히 눈에 띕니다.

이 현상은 우리가 “평균의 함정”이라고 부르는 것과 관련이 있습니다. 평균의 함정을 설명할 때, 식당에 빌 게이츠가 들어오는 예를 흔히 듭니다. 식당에 사람이 9명 있는데, 평균 재산이 1억원이라고 해 봅시다. 그 때 빌 게이츠가 들어오면 식당에 있는 사람의 평균 재산은 (대략) 10조원이 됩니다. 10명중 9명은 평균에 비해서 까마득하게 적은 재산을 가지는 겁니다. 이제 식당 사람들 재산을 노멀라이즈해 봅시다. 평균은 10조, 표준편차는3162억. 9명은 (1억-10조)/3162억 = -31.6. 빌게이츠는 (100조-10조)/3162억 = 284. 노멀라이즈를 하면 평균이 0이 됩니다. 하지만 한 사람만 제외하고 나머지 대다수의 평균을 구해보면 이 경우엔 -31.6이 됩니다.
저자들은 신경망이 최적화되는 과정에서 이 점을 이용한 것으로 봤습니다. 네트워크의 모델에 노멀라이제이션이 들어 있으므로, 이 부분의 산출값의 평균은 반드시 0이 돼야 합니다. 하지만 신경망이 최적화 되는 과정에서 레이턴트 이미지의 평균값이 어떤 중요한 정보전달의 수단이 되었던 것 같습니다. 그래서 이미지의 특정 부분은 특이한 자국이 되도록 희생을 해서, 전체의 평균은 0으로 맞추더라도, 나머지 부분이 원하는 값으로 전달되도록 한 것입니다.
그래서 저자들은 어떻게 했냐고요? AdaIN에서 평균을 조절하는걸 그만 뒀습니다. 쉽죠?

그랬더니 특이한 자국이 사라졌다고 합니다. 쉬워 보이는 해결책이지만 상당한 눈썰미가 아니고서는 생각하기 쉽지는 않았을 겁니다. 이 연구에서 제시하는 방법은 StyleGAN2라는 이름으로 불립니다.
결국 스타일이라는 것은 레이턴트 이미지에서 표준편차를 조절하는 것만으로 표현이 가능하다는 것을 우리는 알게 되었습니다. 처음 소개한 연구 [Gatys et al., 2016]에서 이렇게 먼 길을 거쳐온 결과, 아주 간결한 진실 하나를 얻은 것입니다.
온스퀘어에서는 소프트웨어 개발자를 상시 채용하고 있습니다.
