지난 글에서는 오버핏이 어떤 원리로 발생하는지 알아보고, 오버핏을 완화하기 위한 대표적인 방법들을 몇 가지 소개했습니다. 이번에는 오버핏을 완화하는 좀 더 발전된 방법들을 알아보겠습니다.
오버핏이 안 일어나게 하는 단순하고 아주 효과적인 방법이 하나 있습니다. 데이터가 아주, 아주 많으면 됩니다. 데이터가 많을 수록 머신러닝이 똑똑해진다는 사실은 아주 보편적으로 확인됩니다. 대규모 언어모델(LLM; Large Language Model)이 급속도로 발전하게 된 핵심 요인 중의 하나도 더 많은 데이터를 사용하게 된 것이 한 몫을 합니다.
레이블과 데이터가 항상 많으면 좋겠지만, 언제나 그런 것은 아니죠. 레이블은 얼마 안 되지만 레이블이 없는 데이터를 활용해서 마치 데이터가 많아진 듯한 효과를 내고 싶을 때가 있습니다. 그럴 때 지난 번에도 다뤘던 세미 수퍼바이즈드 러닝을 활용하면 오버핏을 완화할 수 있습니다.
Temporal Ensembling for Semi-Supervised Learning Laine and Alia, 2017 [arxiv]
삼식이는 휴머노이드 로봇입니다. 엑스레이 사진을 보고 결핵이 있는지 판단하는 공부를 매일같이 하고 있습니다. 유감스럽게도 레이블이 있는 엑스레이 사진이 무한정 많지는 않습니다. 몇 안 되는 사진의 레이블에 오버핏하지 않게 하기 위해 방법을 찾기로 했습니다. 엑스레이 사진을 구긴 다음에, 삼식이가 사진에 결핵이 있는지 없는지 판독합니다. 같은 사진을 새로 다시 구긴 다음에, 삼식이가 사진을 다시 판독합니다. 이 두 번의 판독은 같아야 마땅합니다. 엑스레이를 구겼다고 해서 없던 결핵이 생기는 것은 아니니까요. 이와 같이, 레이블이 없더라도, 판독결과가 일관되어야 한다는 제약조건을 걸어서 학습에 활용할 수 있습니다. 이것이 이 연구에서 제안하는 Π-모델의 핵심입니다. 아래 다이어그램에서 와 가 “squared difference”되는 부분이 방금 설명한 판독이 일관되어야 한다는 제약조건을 나타내고 있습니다.
이 연구에서는 템포럴 앙상블링이라고 불리는 또 다른 방법도 제안합니다. 비유를 들어 설명하면 이렇습니다. 삼식이는 매일 한 번씩 전체 엑스레이 데이터를 학습합니다. 삼식이는 날마다 구겨진 엑스레이를 판독한 결과를 잘 보관해 놓습니다. 보관할 때에는 지금껏 판독했던 결과를 평균낸 것을 보관해 놓습니다. 삼식이는 매일 학습해나가고 있으므로 판독결과가 매일 조금씩 바뀝니다. 영순이를 찍은 엑스레이를 그저께 판독했을 때, 결핵이 있을 확률이 0.8이었고, 어제 판독했을 때, 결핵이 있을 확률이 0.7이었다고 해 봅시다. 그럼 삼식이가 영순이의 엑스레이에 대해서 평균적으로 0.75확률로 판정한 것입니다. 그럼 영순이가 결핵이 있는 건가요? 확실하게는 모릅니다. 영순이 엑스레이에는 레이블이 없어요. 하지만 삼식이가 오늘 판독한 결과가 그 전까지 판독의 평균인 0.75에서 아주 많이 벗어나지는 않는 편이 합리적입니다. 여러 판독을 종합한 값은 어느정도 믿을 만하다고 간주하는 것이지요. 이렇게 학습이 진행됨에 따라 판독한 결과가 너무 갑자기 바뀌지 않도록 제약을 가하는 것이 아래 다이어그램에서 설명하는 템포럴 앙상블링의 요점입니다.
여기서 가 구겨진 엑스레이를 오늘 판독한 것에 해당하고, 는 그 전까지의 영순이 엑스레이 판독값들을 평균낸 것입니다. 오늘 판독한 는 평균값 를 업데이트하기 위해 쓰여집니다.
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results Tarvainen and Valpola, 2017 [arxiv]
삼식이는 로봇이므로 뇌 상태를 저장할 수 있습니다. 삼식이가 매일 조금씩 엑스레이 판독을 배워나가는 가운데, 매일매일의 뇌 상태를 저장해 놓습니다. 저장할 때에는 그동안 매일마다 달랐던 뇌 상태의 평균값을 저장합니다. 평균화된 뇌 상태는 매일매일 달라지는 삼식이의 뇌 상태보다 조금이라도 더 믿을 만하다고 간주하는 것입니다. 이렇게 평균낸 것을 민 티처라고 부르기로 합시다.
영순이를 찍은 엑스레이는 레이블이 없습니다. 민 티처가 영순이 엑스레이를 판정해서, 결핵이 있을 확률이 0.66로 산출했다고 합시다. 이 판정을 잠정적으로는 믿기로 합니다. 오늘의 삼식이는 영순이에게 결핵이 있을 확률이 0.66인 것으로 간주하고 배웁니다.
이것이 민 티처(mean teacher)의 핵심입니다. 앞서 다뤘던 템포럴 앙상블링에서는 판정 결과값을 평균하여 보관하는 것인데, 민 티처에서는 신경망의 가중치를 평균하여 보관하는 것이 핵심적인 차이점입니다.
Averaging Weights Leads to Wider Optima and Better Generalization Izmailov et al., 2018 [arxiv]
삼식이가 학습을 해나가는 가운데, 매일 달라지는 뇌 상태의 평균을 저장해 둔다고 했습니다. 그게 더 믿을 만하다고 간주하고요. 그럼 그 평균해서 저장해 둔 삼식이 뇌를 최종 버전으로 간주하고 그냥 트레이닝을 종료시키면 되지 않을까요?
네 됩니다. 그게 민 티처 방법보다 더 구현하기 쉽습니다. 레이블이 없는 데이터를 생각할 필요도 없고, 신경망에 레이블 없는 데이터로 뭘 더 트레이닝시키는 과정도 없습니다. 그냥 평범한 머신러닝 방법대로 트레이닝 하다가, 후반부의 몇 개 버전의 모델을 골라서 평균내 버리는 것이므로, 추가로 들어가는 연산도 없고, 추가로 필요한 데이터도 없고, 코드도 매우 간단합니다. 그럼에도 테스트 정확도가 추가로 조금 더 상승합니다. 성적 향상을 거의 공짜로 즐기는 셈입니다. 이 방법은 SWA (stochastic weight average)라 부릅니다.
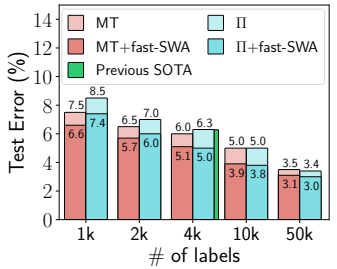
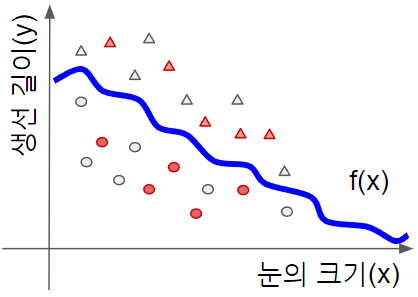
삼식이의 연어 통조림 공장에서는 컨베이어 벨트를 타고 가는 생선 중에 연어만 골라내고 싶습니다. 생선의 눈의 크기와 생선의 길이만 측정해서 연어인지 연어가 아닌지 맞추는 머신러닝 문제가 있다고 생각해 봅시다. 각 생선으로부터 측정된 값들은 아래처럼 2차원 도표에 그릴 수 있습니다.
연어는 원형, 연어 아닌 것은 삼각형으로 표시합시다. 여기서 회색인 것들만 트레이닝에 사용하고 빨간 색으로 된 것은 숨겨놨다가 트레이닝이 끝난 다음, 머신러닝 모델의 성적을 측정하는 데 쓰기로 합시다. 회색 점들을 트레이닝 셋, 빨간 점들을 테스트 셋이라 부릅니다.
먼저 에 관한 0차함수로 맞춰보기로 합시다. 0차함수는 아래와 같은 함수로 나타내죠
어떤 생선의 눈의 크기 와 생선 길이 가 주어질 때, 이면 연어가 아닌 것으로 예측하기로 합시다. 머신러닝 트레이닝은 여기에 알맞은 값을 찾아내는 것이 됩니다. 0차함수는 아래처럼 데이터에 맞춰볼 수 있습니다.
파란색 선의 아랫부분이면 연어인 것으로 예측하는 것입니다. 보다시피 0차 함수로는 어떻게 해도 모든 데이터에 완전히 맞출 수는 없습니다. 파라미터가 한 개밖에 안 되기 때문입니다. 이렇게 파라미터가 부족해서 데이터에 핏이 잘 되지 않는 것을 높은 바이어스(high biase)라고 표현합니다.
이제 데이터를 1차 함수에 맞춰 봅시다. 1차 함수는 아래처럼 표현됩니다.
파라미터가 로 두 개가 되었습니다. 핏한 결과를 차트로 그려보면 아래처럼 될 수 있습니다.
적당히 잘 맞아 보입니다. 테스트용 데이터도 잘 맞았는지 살펴봅시다.
빨간 색으로 표시된 테스트용 데이터도 완벽하게 잘 맞았네요. 원래 이 예제는 1차원 함수에 적합하도록 일부러 만든 것이긴 하지만요 😊😊😊
파라미터를 더 늘려봅시다. 아래와 같은 에 대한 32차원 함수를 생각해 봅시다.
파라미터의 갯수가 많아진 만큼, 복잡한 형태의 곡선을 표현할 수 있습니다. 아래처럼요.
[그림 5] 요동치는 파란 선
동그라미는 모두 선 아래쪽에 있고 삼각형은 모두 선 위쪽에 있으니까 분류가 잘 되었죠? 그런데 뭔가 찜찜하지요? 테스트용 데이터를 넣어서 얼마나 맞았는지 볼까요?
10개의 빨간 것들 중에 5개가 잘못 분류되었습니다. 파라미터를 늘렸더니 트레이닝용 데이터에만 잘 맞고 테스트용 데이터에는 맞지 않는 경우가 생겼습니다. 이런 현상을 높은 베리언스(high variance)라고 합니다.
머신러닝 트레이닝을 할 때, 테스트 로스는 지속적으로 감소하는 가운데 트레이닝 로스가 점점 높아지는 현상은 아주 보편적으로 일어납니다. 이것을 오버핏(overfit)이라고도 부릅니다.
파라미터가 많으면 오버핏이 발생할 수 있습니다. 그런데, 반드시 꼭 그렇기만 한 것은 아닙니다. 파라미터가 많아도 베리언스가 높지 않을 수 있어요. 아래 그림을 보세요.
위 예제는 이해를 돕기 위해 일부러 단순화시켰기 때문에 파라미터가 많으면서도 오버핏하지 않는 함수가 구하기 쉬워 보일 지도 모르겠습니다. 하지만 실제의 데이터들은 아주 고차원이고, 머신러닝 모델의 파라미터도 수백만~수천억개에 이릅니다. 어디에 그릴 수도 없고 머리로 상상하기도 불가능한 세계입니다.
이런 환경에서 오버핏을 막는 방법들 중 아주 대표적인 것들을 몇 가지 소개하겠습니다.
얼리 스토핑 (early stopping)
트레이닝 초반에는 테스트 셋(위의 예에서 빨간색 점)에도 트레이닝 셋(위의 예에서 회색 점)에도 잘 맞지 않습니다. 그러다 점차 트레이닝이 진행되면서 머신러닝 모델이 트레이닝 셋에 맞춰가게 되는데, 이에 따라 테스트용 데이터에도 맞아가게 됩니다. 아래 차트가 시간에 따라 머신러닝 모델이 데이터에 맞아가는 추이를 전형적으로 보여줍니다.
트레이닝이 진행되다 어느 순간부터는 테스트 셋에 잘 맞지 않게 되는 때가 오는데, 그 때가 오기 직전에 트레이닝을 종료하는 겁니다. 싱겁죠?
웨이트 디케이 (weight decay)
파라미터 값들이 커지지 않도록 다음과 같이 머신러닝의 최적화 목표를 추가해 줍니다.
앞서 들었던 예제에서 오버핏이 일어나는 경우를 생각해 보세요 ([그림 5] 요동치는 파란 선). 파라미터의 값들이 크면 클 수록 곡선이 요동치기 마련입니다. 파란 선이 얌전하게 이어지려면 전반적으로 값들이 작아야 합니다. 웨이트 디케이는 선이 요동치지 않도록 가장 명시적으로 제약조건을 주는 방법입니다.
드롭아웃 (dropout)
트레이닝 과정에서 파라미터의 일부가 랜덤 선택되어 거기에 일시적으로 0을 할당하고 트레이닝하는 방법입니다. 두뇌에 비유를 들자면, 뇌세포가 개별적으로 랜덤하게 잠깐씩 작동을 멈추는 걸로 생각할 수 있습니다. 식으로 표현해 보면,
위와 같이 랜덤하게 몇몇 항을 0으로 할당해 버리는 것입니다. 그럼에도 불구하고 전체적으로 정상 작동하도록 트레이닝 목표가 주어지는 것이지요.
레이블 스무딩 (label smoothing)
연어인지 아닌지 판단하는 앞서의 예로 돌아갑시다. 레이블은 연어인 경우 [1.0, 0.0], 연어가 아닌 경우 [0.0, 1.0]으로 주어집니다. 이 때 첫 번째 숫자는 연어일 확률, 두 번째 숫자는 연어가 아닐 확률로 해석할 수 있습니다. 그런데 세상에 100%라는 게 없잖아요? 약간의 절충을 가해서, 연어인 경우 [0.99, 0.01], 연어가 아닌 경우 [0.01, 0.99]이런 식으로 레이블을 공급하는 방법이 레이블 스무딩입니다. 이렇게 스무딩이 들어가는 레이블이 공급되면, 머신러닝이 이미 잘 예측하고 있는 데이터에 대해서는 더이상 학습을 하지 않게 됩니다 (왜 그런지 분석하려면 약간 수학적인 전개가 등장하지만, 일단 넘어가겠습니다). 쉬운 문제는 놔두고 어려운 문제에 집중하는 원리로 “요동치는 파란 선”이 덜 생기게 되는 것입니다.
특별한 사정이 없는 경우에는 머신러닝에서 사용하는 수들은 float32자료형으로 저장합니다. 적당한 정밀도를 제공하고, GPU에서도 가장 일반적으로 처리해주는 자료형이기 때문입니다. float32는 이름에서도 나타나듯이, 32비트 자료형입니다. 수 하나를 표현하기 위해 4바이트를 사용합니다. 한편, GPU는 16비트 자료형인 float16도 처리할 수 있습니다. 이것은 메모리를 절반만 차지하기 때문에, 용량이 큰 인공신경망을 처리하는데 유리합니다. 게다가 float16은 속도가 더 빠르다는 장점이 있습니다. NVIDIA에 따르면, float16으로 연산하면 연산속도가 최대 4.5배 빨라진다고 합니다.
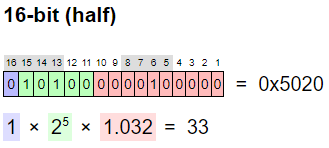
그럼 그냥 float16만 쓰면 되지 왜, “특별한 사정이 없는 경우” float32를 기본으로 쓸까요? 수를 컴퓨터로 표현하는 데에는 한계가 있기 때문입니다. 용량을 절약해서 표현할 수록 그 한계가 금방 나타납니다. 구체적으로 어떤 한계인지 알아봅시다. float16은 2진수로 저장될 때 아래와 같이 세 가지 부분으로 구성됩니다.
보라색 부분은 음수인지 양수인지 표시하는 부분이고(1또는 -1을 나타냄), 녹색 부분은, 표현하려는 수가 2의 몇제곱에 가까운지를 나태내는 부분이고(에서 까지 나타냄), 붉은색 부분은 표현하려는 수를 정밀하게 조절하는 부분으로, 1이상 2미만의 수를 나타냅니다.
이 자료형을 머신러닝에 사용할 때, 구체적으로 어떤 부분 때문에 한계가 발생하는 것일까요?
float16은 아주 작은 수를 표현하지 못하기 때문 아닌가요?
그렇지는 않습니다. float16도 머신러닝에 필요한 만큼은 작은 수를 표현할 수 있습니다. 무려 1천만분의 1까지 표현할 수 있습니다.
float16이 문제가 되는 때는, 아주 작은 수와 큰 수를 더할 때 발생합니다. 무슨 뜻인지 좀 더 자세히 알아보겠습니다.
위 그림은 33을 float16으로 표현한 것입니다.
33보다 큰 수 중에 가장 작은 것은 33.04입니다. 33과 33.04사이의 수는 float16으로는 표현할 수 없습니다.
위 그림은 100만분의 3을 float16으로 표현한 것인데요. 만약 0.000003과 33을 더하면 어떻게 될까요? 33.000003이어야 마땅하겠지만, 앞서 말한 것처럼 float16으로는 표현할 수 없어서, 가장 가까운 수인 33이 나옵니다. float16에서는 33 + 0.000003 = 33 입니다.
반면, float32에서는 33.000003을 표현할 수 있습니다. 그래서 큰 수와 작은 수를 더할 때에는 float32를 써야 합니다.
덧셈 말고 곱셈을 할 때에도 같은 문제가 생기나요?
좋은 질문입니다. 두 수를 곱할 때 어떤 일이 일어나는지 봅시다. 와 를 곱해 봅시다.
여기서 a와c는 덧셈을 하고 있습니다. 따라서 x가 큰 수(a가 양수)이고 y가 작은 수(c가 음수)라고 하더라도, 둘을 곱하는 경우에는 정밀도 때문에 큰 문제가 생기지는 않습니다.
머신러닝에서 곱셈을 많이 쓰는 때는 매트릭스 곱을 할 때입니다. 매트릭스 곱셈 안에는 실수 곱셈 연산이 여러 번 들어갑니다. 이 때 float16을 사용하면 메모리를 절약하면서 연산속도도 빠르게 할 수 있습니다. Dall-E에서는 리지듀얼 블럭에서 신경망의 가중값을 곱하기 직전에 float16으로 변환하고, 직후에 다시 float32로 변환하는 것을 볼 수 있습니다. 아래 그림을 보세요.
출처: Zero-Shot Text-to-Image Generation (Figure 4)
위 그림의 위아래에는 기호가 있습니다. 벡터를 항목별로 더하는 것입니다. 앞서 말했듯 덧셈을 할 때에는 큰 값과 작은 값들이 더해질 우려가 있으므로 float32를 사용하는 것이 바람직합니다.
float32를 사용해야 하는 또 다른 중요한 곳은, SGD나 Adam등을 사용해서 가중값을 최적화하는 부분입니다. SGD는 보통 아래와 같이 표현되는데요,
여기서 두 번째 항 은 보통 아주 작은 값인데, 이 값을 잘 보존하면서 덧셈하는 것이 중요합니다. 때문에 가중값 최적화 부분에서는 float32를 사용해야 합니다.
기계학습에 공급되는 레이블은 대체로 누군가의 고된 노동으로 마련됩니다. 워낙 재미는 없는데 집중력은 필요한 작업이다 보니 디지털 시대의 곰 눈 붙이기라고 부르기도 합니다. 작업 단가를 낮추기 위해서 얼굴 모르는 사람에게 아웃소싱을 주는 플랫폼도 많이 사용합니다. 그런데 이런 식으로 수집된 레이블이 결과물이 백퍼센트 올바를까요? 인터넷을 통해서 대량으로 다운로드받을 수 있는 데이터셋을 이용하는 경우도 있지요. 그 경우도 안심할 수 있을까요? 누가 오류가 있는 레이블만 따로 모아준다면, 그것만 다시 올바르게 레이블링 하겠지만, 수많은 레이블 중에서 어디가 틀려있는지 찾는건 만만치 않습니다. 전체를 재검토할 시간에 새로운 레이블을 그냥 계속 더 만들어내는게 비용상 효율적일 수 있습니다. 그렇다면 발상을 바꿔서, 레이블에 어느정도의 오류가 있다는 것을 인정하고, 오류가 있더라도 트레이닝이 결과적으로 잘 되는 방법이 없을까요? 이번 글에선 이런 문제의식에서 나온 연구들을 살펴보겠습니다.
오류가 있는 레이블들은 더티 셋 dirty set 이라 합니다. 오류가 없는 레이블들은 클린 셋 clean set이라 합니다. 이 분야 연구들은 주로 이 두 레이블 집합의 트레이닝 과정 중에 나타나는 차이에 대해서 관찰하고, 나름의 가설에 따라서 해결책을 제시합니다.
Decoupling “when to update” from “how to update” Malach and Shalev-Shwartz, 2017 [arxiv]
비유를 들어 봅시다. 문제집을 푸는데, 답안지에 대한 신뢰가 좀 떨어지는 상황이라고 합시다. 성적이 상위권인 삼식이와 삼순이가 각각 문제를 풀어서 답안지와 대조해 봅니다. 13번 문제는 답안지에는 정답이 3이라고 되어 있지만, 삼식이와 삼순이는 둘 다 5라고 썼습니다. 답안지에 오류가 있다고 했는데, 그럼 이 13번 문제는 답안지가 틀린 것이 아닐까 의심해볼 수 있습니다. 이럴 때, 삼식이와 삼순이는 둘이 함께 같은 내용으로 대답한 문제는 더 공부할 필요가 없는 것으로 간주하고, 둘의 응답이 엇갈린 문제만 집중해서 공부하기로 합니다.
아래 알고리즘은 지금까지 얘기한 비유를 다른 말로 표현한 것입니다.
Co-teaching: Robust training of deep neural networks with extremely noisy labels Han et al., 2018 [arxiv]
삼식이가 문제집을 풉니다. 문제 100개를 풀었습니다. 채점을 하기 전에, 풀었던 문제들에 대해서 각각 얼마나 확신하는지 삼식이한테 물어봅니다. 어떤 문제는 맞출 자신이 있다고 말하고 어떤 문제는 잘은 모르겠다고 말하겠지요. 이 중 가장 자신이 없는 문제 순으로 10개는 제외하고 90개의 문제에 대해서 답안과 대조를 하고 채점을 해서 학습을 합니다.
답안지에 약간의 오류가 있는 경우에는 이 방법이 효과가 있습니다. 같은 문제집을 여러 번 풀면서 (에포크라고 부릅니다) 점차 학습을 해 나가는 과정에서, 답안지에 오류가 있으면 삼식이가 답안지와 다른 답을 낼 확률이 높습니다. 오답을 기록한 문제는 학습과정에서 조금씩 답안지가 요구하는 결론으로 응답을 바꾸게 되는데, 그 과정에서 필연적으로 예측에 대한 확신이 떨어지는 때가 옵니다. 이렇게 학습자에게 확신이 적은 문항은 답안지가 틀렸을 확률이 높은 것으로 간주하고 학습에서 제외하는 것입니다. 이 방법은 small loss selection이라 부릅니다.
하지만 이 방법에는 문제가 있습니다. 삼식이에게 무슨 문제를 빼고 싶냐고 물어보는 셈이 되기 때문에, 배우기 까다로운 문제는 자신이 없다고 말하고 빼버리는 수가 있지요. 성적이 아주 하위권이라면 대세에 상관이 없고, 이게 오히려 더 효율적인 학습전략일 수 있습니다. 하지만 일정 수준 이상의 성적을 거두고 나면, 배우기 어려운 부분은 영영 빼버리고 만만한 문제만 풀기 때문에 성적이 오르는 데 한계가 뚜렷하겠죠.
전략을 조금 바꿔 보겠습니다. 두 명이 공부를 하는 겁니다. 삼식이와 삼순이가 같은 문제 100개를 각자 풉니다. 삼식이에게 가장 확신이 없는 문제 10개를 제외하고 90개의 문제를 뽑습니다. (삼식이가 아니라) 삼순이는 그 90개의 문제를 답안지와 자신의 풀이를 대조해 보고 학습을 합니다. 이번엔 반대로 삼순이에게 가장 확신이 없는 문제 10개를 제외하고 90개의 문제를 뽑습니다. 삼식이는 그 90개의 문제를 답안지와 자신의 풀이를 대조해 보고 학습을 합니다. 이렇게 하면 내가 어렵다고 생각하는걸 내 학습에서 제외하는 것을 막을 수 있습니다. 나는 남이 어렵다고 생각하는걸 빼고 풀게 되거든요.
Source: Co-teaching: Robust training of deep neural networks with extremely noisy labels
[참고] 비유로 든 문제풀이에서 삼식이가 풀이에 대해 얼마나 자신있는지는, 기계학습 용어로 confidence에 가깝긴 합니다. 논문에서 언급하는 로스와 기술적으로는 차이가 있습니다. 이해를 돕기 위한 비유이니, 어떤 원리로 작동하는지 알게 되었다면 그것으로 비유의 목적을 달성한다고 생각합니다.
Early-Learning Regularization Prevents Memorization of Noisy Labels Liu et al., 2020 [arxiv]
아래에 소개된 가 이 연구에서 제안하는 로스입니다.
는 분류기(classifier)에서 흔히 사용하는 크로스 엔트로피 로스입니다. 원래 다들 하고 있는 것이니 특별할 게 없습니다. 이 연구에서는 두번째 항을 추가한 것이 핵심인데요. 찬찬히 살펴보겠습니다. 은 미니뱃치 안에 들어간 데이터 갯수고, 는 와 균형을 맞추려고 넣은 가중값입니다. 는 트레이닝 중이던 신경망이 데이터 에 대해서 산출한 예측값이고, 트레이닝 과정에서 변화해온 값들을 평균해서 산출한 것이 입니다. < , > 모양은 벡터의 내적을 뜻합니다.
이게 다에요. 구현도 간단하고 계산도 빠릅니다. 트레이닝 셋의 데이터 각각에 대해서 값만 추가로 더 저장하고 있으면 됩니다. 이 로스를 사용하면 레이블에 노이즈가 있어도 트레이닝이 효과적으로 된다고 합니다. 다시한번 식을 잘 보세요. 정말 그래 보이나요? 사실 저는 “어째서?” 라는 의문이 금방 해결되지는 않았습니다.
식 안에 숨어있는 함의를 좀 더 숙고해 봅시다. 는 소프트맥스를 거쳐서 나온 값입니다. 그러므로 벡터의 각 원소의 합은 1로 맞춰져 있습니다. 고양이인지 강아지인지 맞추는 분류기인 경우, 예컨대 이렇게 고양이일 확률 0.8, 강아지일 확률 0.2로 해석할 수 있습니다. 발생할 수 있는 값은 아래 그림처럼 직선 위에 나타납니다.
는 트레이닝 과정에서 변해온 의 평균이라고 했습니다. 짧게 말해 예전 값입니다. 예컨대 라고 해 봅시다. 가장 최근의 값인 이 위 그림처럼 가 나왔다고 하면, 입니다.
다른 예로 위 그림처럼 인 경우에는 입니다. 보셨나요? 과거의 값들에 비해서 최근 예측값 이 더 치우친 예측을 할 때 (고양이일 확률 0.8로 더 강한 확신을 보일 때), 내적은 더 큰 값을 산출하고, 이는 전체 로스를 더 낮추는 기울기를 만들어냅니다.
1에 가까워질수록 까마득하게 값이 하락합니다.
이게 레이블 노이즈와 관련있는 이유는 이렇습니다. 학습 초기에는 어느 한 쪽으로 치우친 예측이 나오기 어렵습니다. 학습이 중간쯤 진행되었다고 해보면, 예측에 자신감이 생기면서 그에 따라 좀 더 분명한(치우친) 예측값이 나오겠죠. 레이블에 노이즈가 있는 경우에는 적당히 트레이닝된 신경망은 예측값과 레이블이 서로 다를 확률이 높습니다. 이러면 크로스 엔트로피 로스 에 따라서 예측값이 레이블 쪽으로 이동하려고 하겠죠. 하지만 이미 한번 치우쳐버린 예측값을 되돌리려면 로스를 많이 높이게 됩니다. 위의 log(1-x)그래프를 보면 1에 가까워질 수록 빠져나오기 힘든 수렁으로 들어가는걸 보실 수 있습니다. 다시 말해 한 번 고양이인것 같다고 추측하기 시작했으면, 기존 추측을 강화하는 쪽으로 변하는 것이 유리하지, 다시 예측을 바꿔서 강아지일 확률이 더 높다고 하기는 힘들어지는 겁니다. 이 원리로 신경망이 원래의 예측을 번복하고 잘못된 레이블을 따라가는 것을 방지하게 됩니다.
ProMix: Combating Label Noise via Maximizing Clean Sample Utility Wang et al., 2022 [arxiv]
이번 연구에서는 먼저, 앞서 소개했던 small-loss selection을 수행해서 일차로 클린 셋을 뽑아냅니다 (논문의 3절 CSS와 MHCS를 참고). 이 방법은 확신이 없다고 응답한 문항은 답안이 올바르더라도 안 배워버리는 문제가 있다고 했습니다. 달리 말하면 로스가 큰 것으로 분류된 쪽에 여전히 클린 셋과 더티 셋이 섞여있다는 뜻이죠. 이제 이 글의 맨 처음에 소개한 [Malach and Shalev-Shwartz, 2017]의 방법을 사용해서 다시한번 클린 셋을 걸러냅니다. 신경망 두 개를 트레이닝하면서 둘의 예측값이 일치하는 데이터는 레이블이 올바르다고 간주하는 겁니다. 아래 그림에서 빨간 공은 더티 데이터와 클린 데이터가 섞여있는, 노이지 셋을 나타냅니다. 어떻게 분류가 되어가는지 살펴보시기 바랍니다.
Source: ProMix: Combating Label Noise via Maximizing Clean Sample Utility
마른 걸레도 짜겠다는 각오로 클린 셋을 꾹꾹 짜냈습니다. 이러고 남은 더티 셋은 레이블이 없는 것으로 간주해서 세미 수퍼바이즈드 러닝(SSL)을 수행합니다. 버리는게 하나도 없어요. SSL로는 mixup, consistency regulation과 같은 기존에 소개되어 있던 방법을 동원합니다. 위 그림의 회색 상자 부분에 해당합니다. 각각에 대해서 상세하게 다루지는 않겠습니다.
이 논문은 배경이 되는 연구에 대해서 알고 있다면 읽기에 평이합니다. 다만 이걸 따라 구현해서 내 프로젝트에 활용하기에 유리하지는 않은 것 같습니다. 데이터를 분류하는 과정에서 임시로 신경망을 훈련하는 과정도 들어가고, 여러 모듈이 모여서 작동하므로 코드도 심플하지는 않아 보입니다. 그럼에도 온갖 기존 기술을 총동원해서 끝까지 데이터를 활용해 내는 정성이 중요한 것 같습니다. 이 연구는 2022년 현재 여러 벤치마크에서 가장 우수한 성과를 거두고 있습니다.
StyleGAN 논문을 읽다 이해가 안 된다는 분 어서 오십시오. GAN분야를 위주로 공부했던 분들은 StyleGAN의 구조에서 AdaIN이 어떤 역할을 하는지 이해하기 어려웠을 수 있습니다. 식은 간단하지만 이게 스타일이랑 어째서 연관이 있는 것인지 논문에는 구구절절 써있지는 않기 때문입니다. StyleGAN의 작동원리를 이해하기 위해서는 스타일 트랜스퍼 (전이)에 대한 이해가 수반되어야 합니다. 이번 글에서는 StyleGAN에 숨어 있는 스타일 전이 방법이 어떻게 발전해왔는지 알아보겠습니다.
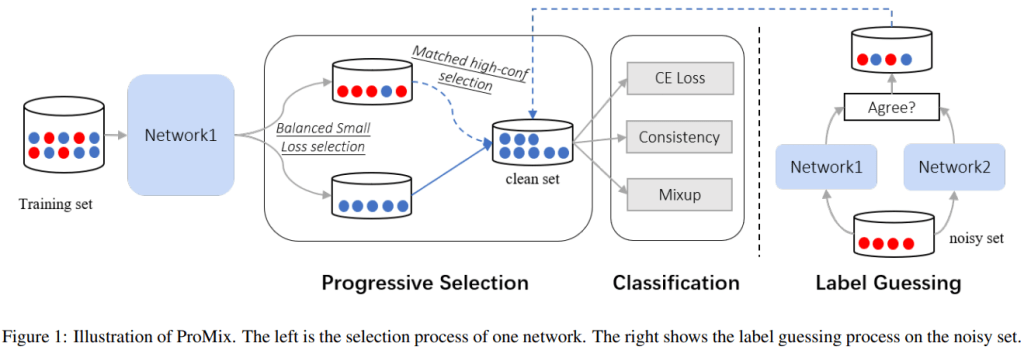
Image Style Transfer Using Convolutional Neural Networks Gatys et al., CVPR 2016 [PDF]
Source: derived based on “Image Style Transfer Using Convolutional Neural Networks”
여러 말이 필요 없습니다. 위의 그림이 스타일 전이가 뭔지 전부 설명하고 있습니다. 스타일 전이는 기계학습이 지금처럼 유행하기 전에도 있었던 방법입니다. 하지만 이 연구에서는 기계학습에 사용되는 인공신경망을 이용해서 스타일 전이를 시도해서 좀 더 유연하고 좋은 품질의 결과를 얻었습니다.
그림이 좀 복잡하지만, 안심하세요. 전부 다 설명하지 않을 겁니다. 전체의 흐름을 파악하는 데에 꼭 필요한 부분만 짚어보겠습니다. 여기서는 영상 인식에 활용하는 VGG네트웍을 이용합니다. 트레이닝이 이미 완료된 것을 사용만 하고 추가로 백 프로퍼게이트는 하지 않습니다. 위 그림에서는 아래로부터 위를 향해 데이터가 흐르는 것으로 묘사되는데, 그림의 각 층은 VGG네트웍의 각 레이어를 뜻합니다. 위로 갈수록 원본 영상으로부터 더 추상적인 특징을 추출해갑니다. (VGG에 대해 이해한다고 여기고 상세하게는 다루지 않겠습니다)
스타일 이미지로부터는 영상의 전반적인 통계를 추출합니다. 이 바로 그것입니다. 이 통계는 스타일 이미지 안에 있는 사물들의 위치에 영향받지 않도록 설계되어 있습니다. 예컨대 위의 예에 있는 스타일 이미지(고흐 그림)을 편집해서 나무가 오른쪽에 있고 달이 왼쪽에 있는 것으로 고쳐서 공급하더라도 의 결과는 크게 바뀌지 않습니다. 하지만 색감을 푸른 색에서 붉은 색으로 영상 전체에 걸쳐서 바뀌도록 편집한다면 이 뚜렷하게 바뀌게 됩니다.
컨텐트 이미지에서는 사물들의 위치를 중요시하게 됩니다. 예컨대 위의 예에 있는 컨텐트 이미지에서 종탑의 위치를 옮긴다면, 결과물에서도 종탑의 위치가 정확하게 따라 옮겨가야 할 것입니다. 이를 위해서는 VGG가 산출하는 각 레이어의 값 을 단지 가져오기만 하면 됩니다.
결과물 이미지 는 처음에 랜덤 노이즈로 시작했다가, 앞에서 소개한 목표들 과 을 따르도록 백프로퍼게이션을 통해 점차 변화시켜가는 방법을 사용합니다. 이 부분은 통상적인 딥러닝과는 다릅니다. 일반적으로 딥러닝에서 백프로퍼게이션을 통해 업데이트하는 것은 인공신경망의 가중값(weight)입니다 (위 그림 참조).
하지만 여기서는 데이터 x를 업데이트하는 것으로 백프로퍼게이션을 수행합니다. 앞서 말했듯 VGG인공신경망의 가중값은 변경하지 않습니다. 이로써 컨텐트와 스타일 이미지를 동시에 따르는 결과물 x가 그라디언트 디슨트 최적화 과정을 통해 점차 완성되는 것입니다.
이 방법의 대표적인 한계점은 연산 시간입니다. 컨텐트와 스타일 이미지가 짝지어 입력으로 주어지면 그 때마다 그라디언트 디슨트를 수행해야 합니다. 결과물 이미지 한 장을 얻기 위해서 상당한 시간을 소요해야 하는 셈인데, 후속 연구들은 이 시간을 단축하는 데 집중합니다. 그리고 이 과정에서 스타일 전이의 본질에 대해서 다른 각도에서 생각해보게 됩니다.
Perceptual Losses for Real-Time Style Transfer and Super-Resolution Johnson et al. 2016 [arxiv]
앞서 소개한 [Gatys et al., 2016]에서는 신경망의 가중값 w을 트레이닝하는 것이 아니라, 데이터 x를 트레이닝한다고 했었습니다. 이번에 소개하는 방법은, 일반적인 인공신경망 최적화 방법대로 가중값 w을 트레이닝합니다. 이렇게 트레이닝된 신경망 는 트레이닝했을 때 주어졌던 한 가지 스타일 전용의 스타일 전이 함수가 됩니다. 뭐든지 손만 닿으면 금으로 변하는 마이다스의 손을 생각하시면 이해가 편합니다. 고흐 스타일용 신경망 가 있다고 해보면, 어떤 컨텐트 목표 를 주던지 그 결과물 는 고흐 스타일로 나타나게 됩니다.
Source: Perceptual Losses for Real-Time Style Transfer and Super-Resolution
트레이닝을 어떻게 하는지 봅시다. 스타일 목표 (예컨대 고흐 그림)을 하나 정합니다 (). 컨텐트 목표는 여러 장을 준비합니다 (). 컨텐트 목표용 이미지들 중에서 한 뱃치를 뽑아 () 위 그림의 자리와 자리에 넣고, 로스 를 최적화하는 신경망 를 구합니다. 위 그림의 오른편에 복잡하게 그려진 로스 는 앞의 [Gatys et al., 2016]에 소개된 것과 사실상 같은 것입니다.
이렇게 하면, 스타일의 갯수만큼 신경망 가 필요하지만, 컨텐트는 어떤 게 주어지든지 상대적으로 빠르게 계산할 수 있습니다. 모든 결과물에 대해서 그라디언트 디슨트를 해야만 했던 [Gatys et al., 2016]에 비한 뚜렷한 발전입니다.
A Learned Representation for Artistic Style Dumoulin et al., 2017 [arxiv]
스타일 트랜스퍼용 모바일 앱을 만든다고 생각해 봅시다. 앞서 소개한 [Johnson et al., 2016] 방법을 사용하면 제공하는 스타일의 갯수만큼 신경망 가중값을 저장해 둬야 합니다. 어림잡아 스타일당 10MB정도의 용량을 차지한다고 가정하면, 10가지 스타일만 제공해도 100MB를 차지하게 됩니다. 고흐 스타일 신경망과 칸딘스키 스타일 신경망이 있다고 해 봅시다. 이 둘은 각자 고유한 부분이 물론 있겠지만, 공유될 수 있는 부분도 있지 않을까요? 신경망을 고유한 부분과 공유하는 부분이 있도록 만들어서 여러 스타일을 한꺼번에 처리하면 파라미터의 수를 절약할 수 있지 않을까요? 이 부분을 해결하기 위해, 스타일이란 무엇인가에 대해 저자들은 독창적인 발상을 하게 됩니다.
저자들은 스타일을 나타낼 때 중요한 요소는 신경망의 각 레이어에서 특징값들의 평균과 표준편차라고 봤습니다. 다시 말해, 특징값들의 평균과 표준편차만 스타일별로 각각 저장하고, 다른 가중값들은 모든 스타일에 공통으로 처리할 수 있을 것으로 봤습니다. 저는 이 내용을 읽었을 때 바로 “아 그럴만 하구나”라고 직관적으로 와닿지는 않습니다. 거꾸로 “이들은 어쩌다 그런게 가능하다는걸 알았나?” 하는 의문이 들었는데, 여기에 대해서 저자들이 논문에 해설해둔 것이 있지만, 결국 어떤 심오한 통찰이 필요했을 것 같습니다. 어쨌거나 정보의 흐름을 도식화하면 아래처럼 그릴 수 있습니다:
Source: A Learned Representation for Artistic Style
신경망의 각 레이어에서, 각 특징값(feature, 또는 채널이라고도 표현하는 그것입니다)별로 평균과 표준편차가 하나씩 저장되어서 하나의 스타일을 정의합니다. 달리 말하면, 인스턴스 노멀라이제이션을 먼저 한 다음 평균과 표준편차를 개별 스타일용 값으로 조정하는 것입니다. 예컨대 가로로 10픽셀이고 세로로 5픽셀이면, 총 50개의 숫자에 대해서 특정 스타일용 평균(위 그림에서 )을 하나 지정합니다. 이 평균과 표준편차들은 트레이너블 파라미터이므로, 백 프로퍼게이션 과정을 통해 로스를 작게 만들도록 최적화됩니다. 로스는 이 글에서 맨 처음 소개한 연구[Gatys et al., 2016]에서 제시된 것과 동일합니다.
논문의 부록에 모델의 세부 명세가 공개돼 있어서, 몇 개의 파라미터가 스타일 하나를 위해 할당되는지 세어 봤습니다. 평균과 표준편차, 이 두 개의 파라미터를 저장하는 데 있어서, 128개의 피처 채널로 이루어진 컨볼루션 레이어 2개가 하나의 리지듀얼 블럭을 형성하는데, 이 블럭이 5개 쌓여 있습니다.
따라서 대략 3천개 안쪽의 파라미터를 추가하면 스타일 하나를 추가할 수 있습니다. 앞서서 소개한 [Johnson et al., 2016]에서는 스타일 하나당 신경망 하나가 통으로 필요했던 것에 비하면 큰 발전입니다. 게다가, 이 추가 파라미터들은 스타일들을 인터폴레이션 하기에도 용이합니다:
Source: A Learned Representation for Artistic Style
용량에 큰 부담 없이 스타일을 추가할 수 있게 되었으니, 이만하면 문제가 뚜렷하게 개선됐다고 볼 수 있습니다. 논문에서는 16가지의 스타일을 한 번에 트레이닝해서 시연하고 있습니다. 하지만 몇 가지의 스타일을 사용할 것인지를 트레이닝 전에 정해야만 합니다. 이 기술로 스타일 전이 앱을 제작한다면, 앱 제작자가 지정한 십수 가지의 스타일 중에서 사용자가 선택할 수는 있겠지만, 사용자가 자신이 만든 이미지를 스타일로 등록할 수는 없습니다.
게다가, 부담이 적다고는 해도 스타일을 무한정 늘릴 수는 없습니다. 이에 따라서 트레이너블 파라미터가 늘어나기 때문입니다. 제공하는 스타일의 갯수의 제약에서 완전히 벗어나는 방법은 없을까요?
Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization Huang and Belongie, 2017 [arxiv]
스타일에 대한 새로운 발상이 또 등장합니다. 이 방법에 의하면 신경망의 파라미터 수가 고정된 채로 스타일을 무한정 사용할 수 있습니다. 임의의 스타일과 컨텐트 이미지 쌍을 입력으로 트레이닝하게 되며, 트레이닝이 끝나면 얼마든지 임의의 스타일 이미지와 컨텐트 이미지를 받아서 결과물을 빠르게 생성할 수 있습니다.
어떤 방법이길래 이게 가능해졌을까요? 직전의 [Dumoulin et al., 2017]에서 평균과 표준편차를 트레이너블 파라미터로 설계했다고 했습니다. 이게 최적화 과정에서 정해지도록 허락하는 것이 아니라, 적절한 값으로 미리 정해서 거꾸로 뉴럴넷에 제공해 버리면 어떨까요? 그럼 뭐가 적절한 걸까요? 저자들은 스타일 이미지 를 VGG에 넣었을 때 산출되는 평균 과 표준편차 를 여기에 활용하기로 했습니다. 이름하여 AdaIN (Adaptive Instance normalization)방법입니다. 식으로는 아래와 같습니다:
여기서 는 컨텐트 이미지입니다. 주어진 컨텐트 이미지의 평균과 표준편차가 스타일 이미지의 평균과 표준편차로 교체되는 과정입니다. 복잡하지 않은 식인데, 단지 이것으로 컨텐트 이미지의 핵심 정보와 스타일 이미지의 핵심 정보가 모두 제공된 것으로 간주하고 트레이닝에 들어갑니다. 트레이닝 과정은 아래 그림을 보시기 바랍니다:
Source: Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization
여전히 로스 와 는 [Gatys et al., 2016]의 것과 동일합니다. 트레이너블 파라미터는 위 그림에서 Decoder부분 뿐입니다.
중간 요점정리
지금까지 스타일 전이 방법에서 트레이닝 전략이 어떻게 바뀌었는지 살펴봤습니다. 처음 소개한 연구 [Gatys et al., 2016]에서 제시한 뼈대에 해당하는 두 가지 아이디어들은 이후의 연구에서도 변함없이 쓰이고 있습니다: (1) 이미 트레이닝된 VGG를 사용해서 중간 레이어의 특징값을 이용한다. (2) 컨텐트 이미지와 스타일 이미지로부터 각각 고유한 로스를 구축한다.
이후의 연구들은 미리 트레이닝한 네트웍으로 빠르게 결과물을 얻는 데 초점을 두었습니다. 조금 더 생각하기 쉬운 방법이 먼저 등장하고, 스타일에 관한 과감한 통찰이 가미되면서 제약이 조금씩 사라져갔습니다. 마지막으로 등장한 AdaIN은 방법 자체는 단순하지만, 지금까지 소개했던 발전의 궤적을 모른다면, 작동원리가 직관적이지 않아서 다소 의아하게 보일 수 있습니다. 이제 최종목표인 StyleGAN으로 가겠습니다. AdaIN을 이해하면 StyleGAN을 아주 쉽게 이해할 수 있습니다.
A Style-Based Generator Architecture for Generative Adversarial Networks Karras et al., CVPR 2019 [arxiv]
GAN의 기본개념에 대해서는 알고 있다고 생각하고 진행하겠습니다. Progressive GAN이라는 고해상도 이미지 트레이닝 방법이 있습니다. 아래 그림의 왼쪽 (a) Traditional에 해당하는 방법으로, 저해상도 이미지로부터 점차 해상도를 높여가며 이미지를 생성하는 방법입니다. StyleGAN도 마찬가지로 저해상도부터 시작하여 해상도를 높입니다. 이 때 AdaIN이 매 레이어마다 설치되었고, 스타일의 평균과 표준편차 역할을 할 정보가 w로부터 공급됩니다. 아래 그림과 그에 수반한 캡션을 찬찬히 보시기 바랍니다.
Source: A Style-Based Generator Architecture for Generative Adversarial Networks
위 그림에서 A라고 표시된 상자가 스타일을 나타냅니다. 이 부분이 이번엔 다시 트레이너블 파라미터가 되었습니다. B 상자는 노이즈를 공급하는데, 결과물 텍스처의 다양성을 표현하는 목적과, 레이턴트 스페이스를 안정화시키는 목적이 모두 있을 것 같습니다 (오토인코더와 베리에이셔널 오토인코더의 차이를 생각해 봅시다). AdaIN덕분에 세밀한 스케일에서부터 거시적인 스케일까지, 각 스케일별로 스타일을 지정할 수 있게 되었습니다. Figure 3에서 보여지는 스타일 전이는 이같은 배경에서 가능해진 것입니다 (Figure 3는 여기에 옮겨 싣지 않았습니다). 여기서는 VGG가 완전히 빠진 것도 생각해볼만 합니다. 뼈대로 하고 있는 Progressive GAN의 영상 생성 능력이 충분하기 때문에 VGG의 특징 추출 능력이 불필요했던 것 같습니다.
스타일 전이는 GAN과는 별개로 여겨진 연구 분야였는데, StyleGAN을 통해서 서로 결합되어서 탁월한 성과를 내는 것을 보면서, 분야를 넘나드는 시각이 중요하다는 것을 다시한번 깨우칩니다.
Analyzing and Improving the Image Quality of StyleGAN Karras et al., 2020 [arxiv]
StyleGAN으로 만들어진 결과물들은 자세히 보면 특이한 자국(artifact)을 볼 수 있습니다. StyleGAN의 모든 결과물에서 나오는데, 레이턴트 스페이스에서 더 확연히 눈에 띕니다.
Source: Analyzing and Improving the Image Quality of StyleGAN
이 현상은 우리가 “평균의 함정”이라고 부르는 것과 관련이 있습니다. 평균의 함정을 설명할 때, 식당에 빌 게이츠가 들어오는 예를 흔히 듭니다. 식당에 사람이 9명 있는데, 평균 재산이 1억원이라고 해 봅시다. 그 때 빌 게이츠가 들어오면 식당에 있는 사람의 평균 재산은 (대략) 10조원이 됩니다. 10명중 9명은 평균에 비해서 까마득하게 적은 재산을 가지는 겁니다. 이제 식당 사람들 재산을 노멀라이즈해 봅시다. 평균은 10조, 표준편차는3162억. 9명은 (1억-10조)/3162억 = -31.6. 빌게이츠는 (100조-10조)/3162억 = 284. 노멀라이즈를 하면 평균이 0이 됩니다. 하지만 한 사람만 제외하고 나머지 대다수의 평균을 구해보면 이 경우엔 -31.6이 됩니다.
저자들은 신경망이 최적화되는 과정에서 이 점을 이용한 것으로 봤습니다. 네트워크의 모델에 노멀라이제이션이 들어 있으므로, 이 부분의 산출값의 평균은 반드시 0이 돼야 합니다. 하지만 신경망이 최적화 되는 과정에서 레이턴트 이미지의 평균값이 어떤 중요한 정보전달의 수단이 되었던 것 같습니다. 그래서 이미지의 특정 부분은 특이한 자국이 되도록 희생을 해서, 전체의 평균은 0으로 맞추더라도, 나머지 부분이 원하는 값으로 전달되도록 한 것입니다.
그래서 저자들은 어떻게 했냐고요? AdaIN에서 평균을 조절하는걸 그만 뒀습니다. 쉽죠?
Source: Analyzing and Improving the Image Quality of StyleGAN
그랬더니 특이한 자국이 사라졌다고 합니다. 쉬워 보이는 해결책이지만 상당한 눈썰미가 아니고서는 생각하기 쉽지는 않았을 겁니다. 이 연구에서 제시하는 방법은 StyleGAN2라는 이름으로 불립니다.
결국 스타일이라는 것은 레이턴트 이미지에서 표준편차를 조절하는 것만으로 표현이 가능하다는 것을 우리는 알게 되었습니다. 처음 소개한 연구 [Gatys et al., 2016]에서 이렇게 먼 길을 거쳐온 결과, 아주 간결한 진실 하나를 얻은 것입니다.
삼식이는 연어를 통조림으로 만드는 회사에 근무합니다. 공급받은 연어가 컨베이어 벨트에서 줄지어 생산라인으로 들어가는데, 가끔 연어가 아닌 생선이 들어오기도 합니다. 컨베이어 벨트 위에 카메라를 달고, 들어오는 생선을 촬영해서 연어인지 아닌지 판단하는 컴퓨터 시스템을 만들려고 합니다. 이 과제는 머신러닝을 이용해서 분류해 보기로 결심했습니다. 컨베이어 벨트로 들어오는 생선 사진은 얼마든지 많이 구할 수 있습니다. 문제는 이게 연어인지 아닌지 알려주는 레이블을 만드는 것입니다. 삼식이는 연어 전문가도 아닙니다. 현장에서 연어를 잘 알아보는 분을 모셔다가 500개 정도 직접 레이블을 만들다 보니 벌써 지쳐갑니다. 다른 방법은 없는지 궁금해졌습니다. 레이블이 없는 데이터는 얼마든지 구할 수 있는데, 이걸 트레이닝에 활용해서 정확도를 높이는 방법이 없을까요? 이런 문제의식에서 나온 것이 세미 수퍼바이즈드 러닝입니다.
Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks Lee, 2013 [link to PDF @ Google Scholar]
레이블이 없는 데이터에 수도(pseudo 가짜) 레이블을 줘가면서 트레이닝 하는 방법입니다. 수도 레이블은 지금까지 트레이닝하던 모델이 예측한 클래스를 적용합니다. 트레이닝이 덜 된 모델이니까 연어가 맞는데도 아니라고 잘못 예측할 수도 있겠죠? 이런 잘못된 수도 레이블을 트레이닝에 사용하면 결과가 나빠질 수가 있습니다. 이런 현상을 확증편향(confirmation bias)이라고 합니다. 저자들도 이걸 알고 있고, 이 문제를 완화하는 방법을 마련했습니다. 로스(loss) 함수를 봅시다:
레이블 수도 레이블 위 식에서 함수 가 두 항의 균형을 맞추고 있습니다. 는 트레이닝 시간 t에 따라 변하게 되어 있는데, 아래처럼 설계되었습니다:
초창기에는 수도 레이블을 로스에 전혀 반영하지 않다가, 만큼 지난 후부터 점차 수도 레이블의 중요성이 증가해서, 에 이르면 최종 가중치 만큼 반영하게 됩니다.
공부를 처음 시작할 때에는 정답지가 있는 문제집만 풀다가, 어느정도 공부를 했을 때부터 정답지가 분실된 문제집도 풀어보는 것으로 비유를 들 수 있겠습니다. 이러면 확증편향에 빠지는 위험보다 레이블이 없는 더 많은 문제를 풀어서 얻는 이득이 더 많아진다고 할 수 있습니다.
Distilling the knowledge in a neural network Hinton et al., 2015 [arxiv]
이 연구에서 다루는 문제는 세미 수퍼바이즈드 러닝은 아닙니다. 하지만 뒤에서 소개할 연구와 깊은 관련이 있어서 언급합니다.
다시 삼식이의 식품공장으로 갑니다. 생선이 연어인지 아닌지 판단한 레이블을 충분히 많이 모았다고 생각해 봅시다. 이제 연어를 분류하는 뉴럴넷을 일단 훈련을 시킵니다. 그렇게 산출된 뉴럴넷을 교사(teacher)라고 부릅시다. 그리고 또다른 뉴럴넷인 학생(student)을 훈련시킵니다. 학생 뉴럴넷은 원래의 레이블이 아니라 교사가 내린 판단을 레이블로 사용해서 학습합니다. 교사의 판단은 하드 레이블이 아니라 소프트 레이블로 적용합니다. 연어가 맞으면 1 틀리면 0으로 레이블 붙이는 것이 하드 레이블이고, 그 사이의 0.8이나 0.4같은 레이블 값도 허용하는 것이 소프트 레이블입니다. 아주 확실히 연어처럼 보이는 것과, 연어인 것 같긴 한데 왠지 자신이 없는 것도 있을 것입니다. 소프트 레이블링은 이런 차이를 트레이닝에 반영할 수 있습니다.
이 연구의 저자가 발견한 중요한 인사이트는, 이렇게 훈련된 학생은 교사보다 과제를 일반화하는 데 더 뛰어나면서, 네트웍의 크기가 작아도 성능에 문제가 없다는 것입니다. 머신러닝에 흔히 사용하는 레이블은 하드 레이블인데, 교사가 소프트 레이블을 제공하기 때문에 이런 장점이 생기는 것 같습니다.
교사가 제공하는 레이블의 부드러운 정도(softness)는 아래 식으로 조절할 수 있습니다:
T=1인 경우는 일반적인 소프트맥스입니다. T가 1보다 작아지면 는 점점 더 부드러운 분포를 갖게 됩니다. 다시 말해 0이나 1에서는 멀어지고 에 점점 더 가까운 값을 산출하게 됩니다.
Self-training with Noisy Student improves ImageNet classification Xie et al., 2019 [arxiv]
수도 레이블[Lee, 2013] 에서의 확증편향은 아무래도 신경이 쓰입니다. 연어가 아닌데 연어라고 결론짓고 그걸 학습한다고 생각하면 껄끄럽죠. 이번 연구에서는 앞선 [Hinton et al., 2015] 에서의 교사-학생 관계와 수도 레이블을 동시에 응용합니다. 앞의 두 연구를 이해한다면 아래 그림만 봐도 이번 연구에서 사용한 방법의 흐름을 금방 이해할 수 있습니다.
Source: Xie et al., 2019
여기서 중요한 점은 교사에 노이즈를 넣는다는 것과, 학생의 네트웍 크기는 교사보다 작지 않다는 것입니다. 학생이 다시 교사가 되어야 하는데 네트웍 크기를 작게 해버리면 다음 세대의 학생은 더 작아지게 되고, 얼핏 생각해도 바람직하지 않지요. 일부러 노이즈를 넣음으로써, 확증 편향에 의한 오류를 어느정도 극복하게 합니다. 일반화를 더 잘 하게 되는 효과도 있을 것입니다. 아래의 알고리즘 스케치를 보고 갑시다:
Fixmatch: Simplifying semi-supervised learning with consistency and confidence Shon et al., 2020 [arxiv]
삼식이한테 선글라스를 씌워주고 저 생선이 뭔지 물어봅니다. 연어라고 대답합니다. 이번엔 더러워서 잘 안 보이는 안경을 씌워주고 아까 그 생선을 가리키며 뭐냐고 물어봅니다. 이번엔 참치라고 대답합니다. 삼식이가 대답을 잘못하고 있다는 것은 확실해졌죠. 안경을 바꿔도 같은 생선은 같은 답을 해야 된다고 훈련시킨다면 이것이 Fixmatch입니다. 방금 본 생선의 실제 레이블은 없어도 됩니다. 응답의 일관성이 훈련의 요점입니다. 아래 그림을 봅시다:
Source: Shon et al., 2020
어째서 이 방법이 세미 수퍼바이즈드 러닝으로 효과가 좋은지는 아주 자명하게 이해되지는 않습니다. 저 나름의 해석은 이렇습니다. 레이블이 없는 데이터는 그것이 영상이든 음성이든, 컴퓨터에서는 정수의 배열로 나타내집니다. 이것은 표현방법에 따라 고차원 공간상의 하나의 점으로 표시할 수도 있습니다. 고차원 공간은 화면에 그리기가 까다로우니 편의상 과감히 2차원까지만 표시해보겠습니다.
이 전체 공간에서 의미있는 영상이 나타나는 곳은 극히 일부분일 것입니다. 주사위를 던져서 나오는 값 대로 한 픽셀씩 색상을 결정했을 때, 랜덤 노이즈 모습의 영상이 나올 확률이 압도적으로 높습니다. 강아지 모습이라던지, 자동차 같은, 영상다운 영상이 나올 확률이 얼마나 되겠습니까? 엄청나게 적은 확률이지만, 0은 아니죠. 이렇게 영상다운 영상이 나오는 구역을 라고 해 봅시다. 이 공간 안에 자동차 영상도 있고, 말 사진도 있고, 비행기의 모습도 있는 것입니다.
이제 어떤 말 영상 가 있는데, 이걸 겨우 알아볼 정도로 심하게 변형시켜서 가 되었다고 해 봅시다. 이렇게 심하게 변형된 이미지가 존재하는 공간을 라고 하면, 는 바로 근처에 있으면서, 의 넓이는 보다는 더 넓다고 볼 수 있습니다. 영상 하나를 갖고서 변형하는 방법은 무수히 많기 때문이지요. 는 안에 있고, 는 안에 있습니다. 이 때 Fixmatch가 와 의 레이블이 같아지도록 트레이닝을 합니다. 우리가 관심있는 부분은 영역에서 올바른 레이블을 예측하는 것이지만, 이 목표를 달성하기 위해서 과의 일관성이 잘 유지되는 것이 유효하다는 것을 추측할 수 있습니다. 시험범위 바깥의 내용을 공부하는 셈입니다. 저는 이것이 효과적인 이유는 은 를 빠짐없이 둘러싸고 있고, 의 넓이가 보다 넓기 때문이 아닐까 생각합니다. 에서 학습한 내용이 로 스며들기에 구조적으로 유리한 형국이기 때문입니다.
A Simple Framework for Contrastive Learning of Visual Representations Chen et al., 2020 [arxiv]
삼식이는 사진속 생선이 연어인지 아닌지에 대해 관심이 있습니다. 먼저, 생선 사진으로부터 알 수 있는 속성들을 나열해 보았습니다. 생선의 길이, 색상, 눈의 크기, 길이와 폭의 비율 등등… 이 중 눈의 크기와 생선의 길이를 선택해서 2차원 차트에다 각 생선 사진들을 점으로 표시해 봤습니다. 그랬더니 연어 사진들은 모두 차트의 한쪽에 모여있는 것을 발견했습니다. 빙고!
(예를 든 것일 뿐 이것이 연어를 식별하는데 실제로 유용한 것은 아닙니다.)
이처럼 원본 데이터를 차트 위에 표현했을 때, 서로 유사한 것끼리 모여 있고, 유사하지 않은 것들은 멀리 떨어져 있다면 분류가 수월해 집니다. 문제는 차트에서 가로축, 세로축을 담당하는 알맞은 척도를 어떻게 찾느냐겠죠. 그것을 머신 러닝을 이용해서 찾아봅시다.
방금 예를 든 것을 힌트로 삼아 형식적으로 정리해 보겠습니다. 데이터D를 어떤 저차원의 임베딩 공간z로 보내는 함수f: D → z가 있을 때, 데이터a,b가 같은 종류이면 f(a)와 f(b)가 가까운 곳에 위치하게 되는 z와 f를 구하는 것을 컨트라스티브 러닝(contrastive learning)이라고 합니다.
위에서 “같은 종류”와 “가깝다”는 것은 구체적으로 뭔지 알아봅시다. 이 연구에서 제안하는 방법, SimCLR은 레이블이 없는 데이터 를 두 가지로 어구먼트(augment)한 , 가 같은 종류인 것으로 정의합니다. 예를 들어 강아지 사진을 좌우 반전해서 로 삼고 흑백으로 만들어서 로 삼습니다. 그러면 와 의 피사체는 동일하므로, 이 관계를 이용하겠다는 겁니다. 가깝다는 것은 공간 z에서의 코사인 유사성으로 정의합니다. 아래 도식과 캡션을 같이 봅시다 (아래에서 h에 관한 언급은 일단은 넘어갑시다).
SimCLR은 앞에서 설명한 Fixmatch [Shon et al., 2020]와 *매우* 비슷합니다. 하나의 데이터에 대해서 두 가지 어구먼테이션이 등장하고, 이 둘 간의 공통점을 이용합니다. 조금 다른 점은 Fixmatch는 세미 수퍼바이즈드 러닝을 염두에 뒀다는 점입니다. 이땐 레이블에 사용할 클래스 목록(예: 개, 고양이, 말)이 존재합니다. 이 클래스 목록에 있는 것 중 하나를 맞추는 것으로 문제가 정의되어 있습니다. 반면, SimCLR은 레이블도 클래스 목록도 없이 데이터만 보고 거기에 내재된 관계를 학습하는 방법입니다. 이를 언수퍼바이즈드 러닝(unsupervised learning)이라고 합니다. 데이터 하나에 대해서 자기 자신의 변형들끼리의 관계를 학습하므로 셀프 수퍼바이즈드 러닝(self-supervised learning)이라고도 합니다.
Source: Chen et al., 2020 개의 품종을 모르는 사람에게도, 위의 개들이 다 같은 품종이라는 것은 자명합니다.
SimCLR의 로스는 아래처럼 정의됩니다:
여기서𝜏는 [Hinton et al., 2015]에서 다뤘던, 부드러운 정도를 제어하는 파라미터입니다.
Supervised Contrastive Learning Khosla et al., NIPS 2020 [arxiv]
앞선 SimCLR [Chen et al., 2020]은 레이블이 필요 없다고 했습니다. 레이블이 있는 경우에도 레이블을 사용 안 해버리면 아깝잖아요? 그래서 이 연구에서는 레이블이 같은 경우는 임베딩 공간(아래 그림에서 원으로 표시)에서도 가깝도록 로스를 설정해 줍니다. 핵심은 이게 다에요. 진짜로.
훌륭한 교사는 학생의 수준에 맞춘 강의를 합니다. 이 연구에서는 학생이 가장 올바르게 배울 수 있도록 교사 네트워크가 백프로퍼게이트됩니다!
수도 레이블에서 하는 일을 되새겨봅시다. (지금부터 정리하는 내용은 [Lee 2013]이나 [Xie et al. 2019]과는 미묘하게 다릅니다.)
교사는 답안지가 없는 문제집 을 이용해서 학생를 가르치면, 교사 지도를 가장 잘 따르는 모범생 이 산출됩니다. 모범생이 공부를 잘 하는지는 답안지가 있는 문제집 을 풀게 해서 검증해볼 수 있습니다:
모범생 은 에 대해서 우수하도록 교육받았지, 에 대해서는 최적화된 적이 없습니다. 학생은 교사로부터만 배우기 때문에, 우수한 교사 밑에서 배워야만 학생의 이 개선됩니다.
을 줄여주는 우수한 교사는 어떤 걸까요? 답안지가 있는 문제집 을 잘 푸는 교사? 아닙니다. 교사가 시험 잘 보는건 의미가 없어요. 학생이 시험 잘 보도록 수업시간(위의 식(1))에 잘 가르치는게 중요합니다. 구체적으로는 에 대해서 최적의 소프트 레이블 를 제공해야 합니다. 최적의 교사는 식으로 나타내면 아래처럼 됩니다:
여기에 부합하게 교사를 백프로퍼게이트하는 미분식 유도는 거의 불가능합니다. 때문에, 저자들은 근사법을 시도하는데, 결론적으로는 학생과 교사가 한 스텝씩 SGD를 번갈아가며 합니다:
위 식이 이해 안 되는 분, 걱정 마세요. 정상입니다. 특히 교사를 업데이트하는 부분은 미분을 전개하기가 무척 까다롭습니다. 논문에는 부록A에 실려 있는데, 야심있는 분들은 도전해 보세요!
Semantic Segmentation with Generative Models: Semi-Supervised Learning and Strong Out-of-Domain Generalization Li et al., CVPR 2021 [arxiv]
이미지 세그먼테이션용 레이블링은 고된 작업입니다. 얼굴에서 정교하게 눈코입머리눈썹을 세그먼트한다고 생각해 봅시다. 트레이닝용 레이블이 10만개쯤 필요하다면 노동의 규모가 굉장할 겁니다. 의료영상처럼 전문지식이 있는 레이블러가 필요한 경우엔 인건비가 더 올라가겠죠. 이 연구에서는 GAN으로 그럴듯한 세그먼테이션과 이미지를 쌍으로 생성해 줍니다:
Source: Li et al., 2021
CoCa: Contrastive Captioners are Image-Text Foundation Models Yu et al., 2022 [arxiv]
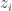





 에 관한 0차함수로 맞춰보기로 합시다. 0차함수는 아래와 같은 함수로 나타내죠
에 관한 0차함수로 맞춰보기로 합시다. 0차함수는 아래와 같은 함수로 나타내죠
 의 눈의 크기
의 눈의 크기  와 생선 길이
와 생선 길이  가 주어질 때,
가 주어질 때,  이면 연어가 아닌 것으로 예측하기로 합시다. 머신러닝 트레이닝은 여기에 알맞은
이면 연어가 아닌 것으로 예측하기로 합시다. 머신러닝 트레이닝은 여기에 알맞은  값을 찾아내는 것이 됩니다. 0차함수는 아래처럼 데이터에 맞춰볼 수 있습니다.
값을 찾아내는 것이 됩니다. 0차함수는 아래처럼 데이터에 맞춰볼 수 있습니다.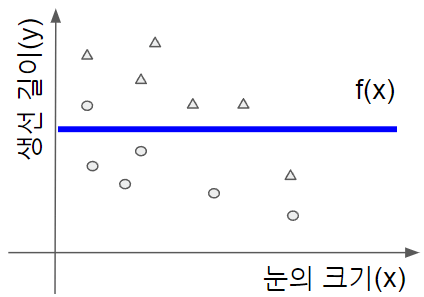

 로 두 개가 되었습니다. 핏한 결과를 차트로 그려보면 아래처럼 될 수 있습니다.
로 두 개가 되었습니다. 핏한 결과를 차트로 그려보면 아래처럼 될 수 있습니다.





 의 일부가 랜덤 선택되어 거기에 일시적으로 0을 할당하고 트레이닝하는 방법입니다. 두뇌에 비유를 들자면, 뇌세포가 개별적으로 랜덤하게 잠깐씩 작동을 멈추는 걸로 생각할 수 있습니다. 식으로 표현해 보면,
의 일부가 랜덤 선택되어 거기에 일시적으로 0을 할당하고 트레이닝하는 방법입니다. 두뇌에 비유를 들자면, 뇌세포가 개별적으로 랜덤하게 잠깐씩 작동을 멈추는 걸로 생각할 수 있습니다. 식으로 표현해 보면,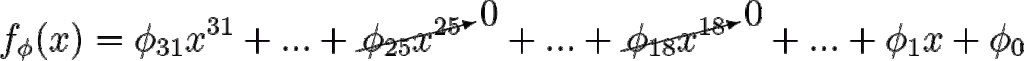

 에서
에서 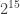 까지 나타냄), 붉은색 부분은 표현하려는 수를 정밀하게 조절하는 부분으로, 1이상 2미만의 수를 나타냅니다.
까지 나타냄), 붉은색 부분은 표현하려는 수를 정밀하게 조절하는 부분으로, 1이상 2미만의 수를 나타냅니다.

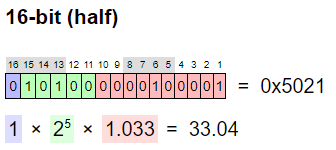


 와
와  를 곱해 봅시다.
를 곱해 봅시다.

 기호가 있습니다. 벡터를 항목별로 더하는 것입니다. 앞서 말했듯 덧셈을 할 때에는 큰 값과 작은 값들이 더해질 우려가 있으므로 float32를 사용하는 것이 바람직합니다.
기호가 있습니다. 벡터를 항목별로 더하는 것입니다. 앞서 말했듯 덧셈을 할 때에는 큰 값과 작은 값들이 더해질 우려가 있으므로 float32를 사용하는 것이 바람직합니다.
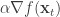 은 보통 아주 작은 값인데, 이 값을 잘 보존하면서 덧셈하는 것이 중요합니다. 때문에 가중값 최적화 부분에서는 float32를 사용해야 합니다.
은 보통 아주 작은 값인데, 이 값을 잘 보존하면서 덧셈하는 것이 중요합니다. 때문에 가중값 최적화 부분에서는 float32를 사용해야 합니다.

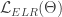 가 이 연구에서 제안하는 로스입니다.
가 이 연구에서 제안하는 로스입니다.
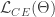 는 분류기(classifier)에서 흔히 사용하는
는 분류기(classifier)에서 흔히 사용하는  은 미니뱃치 안에 들어간 데이터 갯수고,
은 미니뱃치 안에 들어간 데이터 갯수고,  는
는 ![\mathbf{p}^{[i]}](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bp%7D%5E%7B%5Bi%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002) 는 트레이닝 중이던 신경망이 데이터
는 트레이닝 중이던 신경망이 데이터  에 대해서 산출한 예측값이고, 트레이닝 과정에서 변화해온
에 대해서 산출한 예측값이고, 트레이닝 과정에서 변화해온 ![\mathbf{t}^{[i]}](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bt%7D%5E%7B%5Bi%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002) 입니다. < , > 모양은
입니다. < , > 모양은![\mathbf{p}^{[i]} = [0.8, 0.2]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bp%7D%5E%7B%5Bi%5D%7D+%3D+%5B0.8%2C+0.2%5D&bg=ffffff&fg=333333&s=0&c=20201002) 이렇게 고양이일 확률 0.8, 강아지일 확률 0.2로 해석할 수 있습니다. 발생할 수 있는
이렇게 고양이일 확률 0.8, 강아지일 확률 0.2로 해석할 수 있습니다. 발생할 수 있는 
![\mathbf{t}^{[i]} = [0.7, 0.3]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bt%7D%5E%7B%5Bi%5D%7D+%3D+%5B0.7%2C+0.3%5D&bg=ffffff&fg=333333&s=0&c=20201002) 라고 해 봅시다. 가장 최근의 값인
라고 해 봅시다. 가장 최근의 값인 ![[0.8, 0.2]](https://s0.wp.com/latex.php?latex=%5B0.8%2C+0.2%5D&bg=ffffff&fg=333333&s=0&c=20201002) 가 나왔다고 하면,
가 나왔다고 하면, ![\langle\mathbf{p}^{[i]}, \mathbf{t}^{[i]}\rangle = 0.62](https://s0.wp.com/latex.php?latex=%5Clangle%5Cmathbf%7Bp%7D%5E%7B%5Bi%5D%7D%2C+%5Cmathbf%7Bt%7D%5E%7B%5Bi%5D%7D%5Crangle+%3D+0.62&bg=ffffff&fg=333333&s=0&c=20201002) 입니다.
입니다.
![\mathbf{p}^{[i]} = [0.6, 0.4]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bp%7D%5E%7B%5Bi%5D%7D+%3D+%5B0.6%2C+0.4%5D&bg=ffffff&fg=333333&s=0&c=20201002) 인 경우에는
인 경우에는 ![\langle\mathbf{p}^{[i]}, \mathbf{t}^{[i]}\rangle = 0.54](https://s0.wp.com/latex.php?latex=%5Clangle%5Cmathbf%7Bp%7D%5E%7B%5Bi%5D%7D%2C+%5Cmathbf%7Bt%7D%5E%7B%5Bi%5D%7D%5Crangle+%3D+0.54&bg=ffffff&fg=333333&s=0&c=20201002) 입니다. 보셨나요? 과거의 값들에 비해서 최근 예측값
입니다. 보셨나요? 과거의 값들에 비해서 최근 예측값 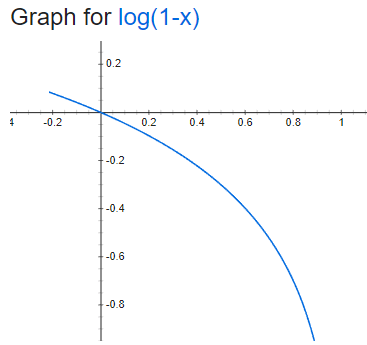

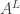 이 바로 그것입니다. 이 통계는 스타일 이미지 안에 있는 사물들의 위치에 영향받지 않도록 설계되어 있습니다. 예컨대 위의 예에 있는 스타일 이미지(고흐 그림)을 편집해서 나무가 오른쪽에 있고 달이 왼쪽에 있는 것으로 고쳐서 공급하더라도
이 바로 그것입니다. 이 통계는 스타일 이미지 안에 있는 사물들의 위치에 영향받지 않도록 설계되어 있습니다. 예컨대 위의 예에 있는 스타일 이미지(고흐 그림)을 편집해서 나무가 오른쪽에 있고 달이 왼쪽에 있는 것으로 고쳐서 공급하더라도  을 단지 가져오기만 하면 됩니다.
을 단지 가져오기만 하면 됩니다.
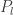 을 따르도록 백프로퍼게이션을 통해 점차 변화시켜가는 방법을 사용합니다. 이 부분은 통상적인 딥러닝과는 다릅니다. 일반적으로 딥러닝에서 백프로퍼게이션을 통해 업데이트하는 것은 인공신경망의 가중값(weight)입니다 (위 그림 참조).
을 따르도록 백프로퍼게이션을 통해 점차 변화시켜가는 방법을 사용합니다. 이 부분은 통상적인 딥러닝과는 다릅니다. 일반적으로 딥러닝에서 백프로퍼게이션을 통해 업데이트하는 것은 인공신경망의 가중값(weight)입니다 (위 그림 참조). 
 는 트레이닝했을 때 주어졌던 한 가지 스타일 전용의 스타일 전이 함수가 됩니다. 뭐든지 손만 닿으면 금으로 변하는 마이다스의 손을 생각하시면 이해가 편합니다. 고흐 스타일용 신경망
는 트레이닝했을 때 주어졌던 한 가지 스타일 전용의 스타일 전이 함수가 됩니다. 뭐든지 손만 닿으면 금으로 변하는 마이다스의 손을 생각하시면 이해가 편합니다. 고흐 스타일용 신경망 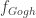 가 있다고 해보면, 어떤 컨텐트 목표
가 있다고 해보면, 어떤 컨텐트 목표  는 고흐 스타일로 나타나게 됩니다.
는 고흐 스타일로 나타나게 됩니다.
 ). 컨텐트 목표는 여러 장을 준비합니다 (
). 컨텐트 목표는 여러 장을 준비합니다 ( ). 컨텐트 목표용 이미지들
). 컨텐트 목표용 이미지들  ) 위 그림의
) 위 그림의  자리에 넣고, 로스
자리에 넣고, 로스 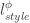 를 최적화하는 신경망
를 최적화하는 신경망 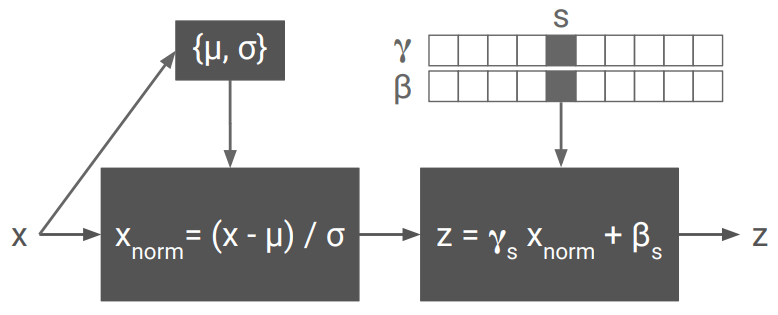
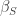 )을 하나 지정합니다. 이 평균과 표준편차들은 트레이너블 파라미터이므로, 백 프로퍼게이션 과정을 통해 로스를 작게 만들도록 최적화됩니다. 로스는 이 글에서 맨 처음 소개한 연구[Gatys et al., 2016]에서 제시된 것과 동일합니다.
)을 하나 지정합니다. 이 평균과 표준편차들은 트레이너블 파라미터이므로, 백 프로퍼게이션 과정을 통해 로스를 작게 만들도록 최적화됩니다. 로스는 이 글에서 맨 처음 소개한 연구[Gatys et al., 2016]에서 제시된 것과 동일합니다.
 를 VGG에 넣었을 때 산출되는 평균
를 VGG에 넣었을 때 산출되는 평균  과 표준편차
과 표준편차  를 여기에 활용하기로 했습니다. 이름하여 AdaIN (Adaptive Instance normalization)방법입니다. 식으로는 아래와 같습니다:
를 여기에 활용하기로 했습니다. 이름하여 AdaIN (Adaptive Instance normalization)방법입니다. 식으로는 아래와 같습니다: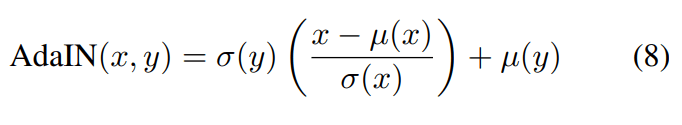
 와
와  는 [Gatys et al., 2016]의 것과 동일합니다. 트레이너블 파라미터는 위 그림에서 Decoder부분 뿐입니다.
는 [Gatys et al., 2016]의 것과 동일합니다. 트레이너블 파라미터는 위 그림에서 Decoder부분 뿐입니다.



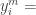 레이블
레이블 수도 레이블
수도 레이블 가 두 항의 균형을 맞추고 있습니다.
가 두 항의 균형을 맞추고 있습니다. 
 만큼 지난 후부터 점차 수도 레이블의 중요성이 증가해서,
만큼 지난 후부터 점차 수도 레이블의 중요성이 증가해서,  에 이르면 최종 가중치
에 이르면 최종 가중치  만큼 반영하게 됩니다.
만큼 반영하게 됩니다.
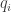 는 점점 더 부드러운 분포를 갖게 됩니다. 다시 말해 0이나 1에서는 멀어지고
는 점점 더 부드러운 분포를 갖게 됩니다. 다시 말해 0이나 1에서는 멀어지고 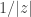 에 점점 더 가까운 값을 산출하게 됩니다.
에 점점 더 가까운 값을 산출하게 됩니다.



 에서 의미있는 영상이 나타나는 곳은 극히 일부분일 것입니다. 주사위를 던져서 나오는 값 대로 한 픽셀씩 색상을 결정했을 때, 랜덤 노이즈 모습의 영상이 나올 확률이 압도적으로 높습니다. 강아지 모습이라던지, 자동차 같은, 영상다운 영상이 나올 확률이 얼마나 되겠습니까? 엄청나게 적은 확률이지만, 0은 아니죠. 이렇게 영상다운 영상이 나오는 구역을
에서 의미있는 영상이 나타나는 곳은 극히 일부분일 것입니다. 주사위를 던져서 나오는 값 대로 한 픽셀씩 색상을 결정했을 때, 랜덤 노이즈 모습의 영상이 나올 확률이 압도적으로 높습니다. 강아지 모습이라던지, 자동차 같은, 영상다운 영상이 나올 확률이 얼마나 되겠습니까? 엄청나게 적은 확률이지만, 0은 아니죠. 이렇게 영상다운 영상이 나오는 구역을 
 가 있는데, 이걸 겨우 알아볼 정도로 심하게 변형시켜서
가 있는데, 이걸 겨우 알아볼 정도로 심하게 변형시켜서  가 되었다고 해 봅시다. 이렇게 심하게 변형된 이미지가 존재하는 공간을
가 되었다고 해 봅시다. 이렇게 심하게 변형된 이미지가 존재하는 공간을  라고 하면,
라고 하면, 
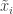 ,
, 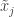 가 같은 종류인 것으로 정의합니다. 예를 들어 강아지 사진
가 같은 종류인 것으로 정의합니다. 예를 들어 강아지 사진





 는 답안지가 없는 문제집
는 답안지가 없는 문제집  을 이용해서 학생
을 이용해서 학생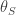 를 가르치면, 교사 지도를 가장 잘 따르는 모범생
를 가르치면, 교사 지도를 가장 잘 따르는 모범생  이 산출됩니다. 모범생이 공부를 잘 하는지는 답안지
이 산출됩니다. 모범생이 공부를 잘 하는지는 답안지 가 있는 문제집
가 있는 문제집 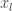 을 풀게 해서 검증해볼 수 있습니다:
을 풀게 해서 검증해볼 수 있습니다:
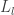 이 개선됩니다.
이 개선됩니다. 를 제공해야 합니다. 최적의 교사는 식으로 나타내면 아래처럼 됩니다:
를 제공해야 합니다. 최적의 교사는 식으로 나타내면 아래처럼 됩니다:



You must be logged in to post a comment.